

This article is intended for you, dear clients, both current and future. Whether you’re looking to build a new application, enhance an existing system, or integrate complex technologies, crafting an RFP that developers will love involves more than just listing technical specifications. It’s about creating a document that not only conveys your project’s vision but also fosters collaboration, innovation, and a mutual understanding of expectations.
In this guide, I will explore key strategies to help you write an RFP that attracts high-quality proposals and sets the stage for a successful partnership with your development team.
This article will help you understand the RFP process in the realm of software development from the developers’ perspective. By gaining insights into how developers interpret and respond to RFPs, you will be better equipped to communicate effectively and align expectations, leading to more successful collaborations and project outcomes. Read More »

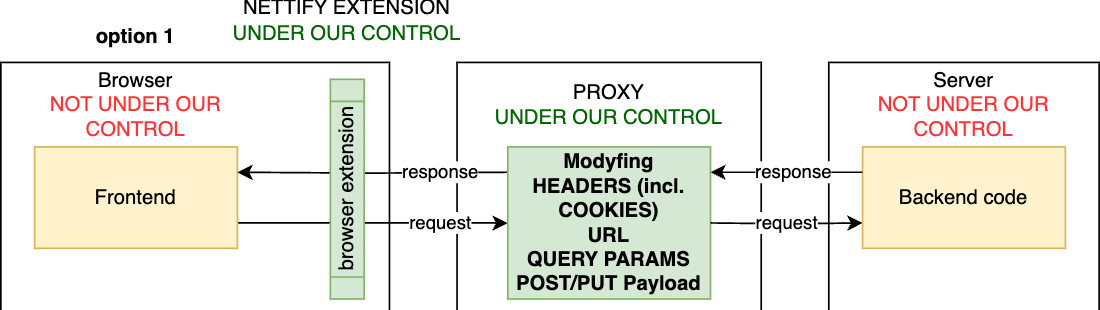
 When working with APIs, dealing with raw JSON for input and output can be cumbersome, especially when there’s a convenient UI designed specifically for that API. However, the UI doesn’t always keep up with changes in the service, and sometimes it’s useful to emulate changes in the service along with the UI to finalize decisions on what and how to modify.
When working with APIs, dealing with raw JSON for input and output can be cumbersome, especially when there’s a convenient UI designed specifically for that API. However, the UI doesn’t always keep up with changes in the service, and sometimes it’s useful to emulate changes in the service along with the UI to finalize decisions on what and how to modify.
Such a solution could allow you to replace actual API responses with tailored fake data, eliminating the need for altering real data or making code changes. It would accelerate slow requests by recording and replaying them, significantly reducing wait times for UI tweaks. Developers could simulate edge cases, such as handling 4XX or 5XX status codes or testing long strings, by modifying response bodies, status codes, or headers, or add a debug/verbose mode automatically to all calls to an API. Additionally, it would enable frontend development against unimplemented APIs by mocking responses, facilitating progress even when backend endpoints are incomplete. For integration with third-party platforms that only function on production domains, such a solution could reroute requests, allowing safe testing on production without risk. Furthermore, it would support debugging by adding artificial delays and simulating network errors, ensuring robust handling of edge cases. In essence, mocking servers on production in your browser would streamline development, enhance testing, and ensure a more resilient application.
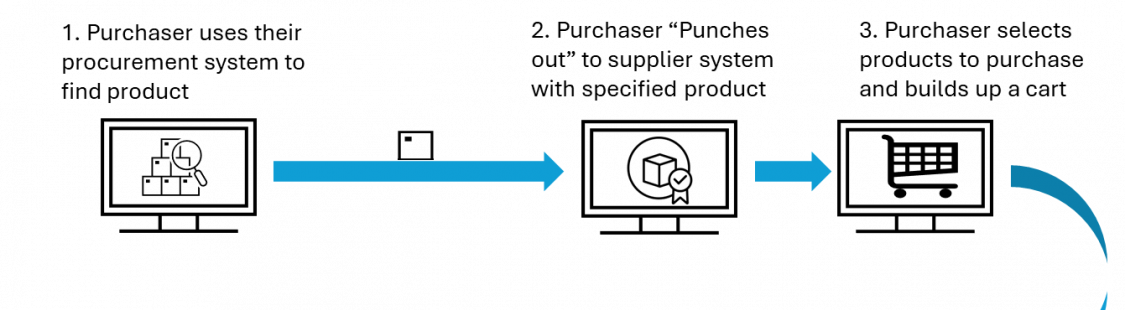
As the “victim,” I chose the SAP Commerce demo store (to whose code I don’t have access to), specifically its search functionality. The goal was to inject my custom code between its backend and frontend, and as a demonstration of capabilities, automatically apply certain facets for specific queries. As a result, for the query “cheap cameras,” I will actually see cheap cameras and not tripods, for example.
Read More »
In one of my projects, it was crucial for me to monitor data volumes and some specific e-commerce system parameters and alert the technical team if there were any abrupt or unexpected changes in them. These fluctuations occasionally (though not always) signaled potential existing issues or an increased likelihood of future problems.
I am focusing on operational parameters (orders, shopping carts, customers, logins, product data quality), not technical (page load time, timeouts).
Due to the lack of built-in solutions in SAP Commerce for this function, I had to design and implement a custom solution from the ground up. This article delves into the specifics of that development process and details of the architecture.
Read More »
In one of my recent personal projects, I ventured into the vast archives of The Saturday Evening Post, a magazine that has captured American life since 1821. What started as a nostalgic dive into the past tu,/rned into a technical quest to make over a century of magazine issues searchable and accessible online.
Utilizing a blend of OCR with Tesseract and search mechanisms based on Apache Solr, OpenAI embeddings, FAISS, ML Re-ranking, I managed to create a searchable database of the magazine’s rich content from 1900 till our days. From Norman Rockwell’s iconic illustrations to pivotal historical articles, every page was digitized and ready to be explored.
This project engagingly occupied several weekends and further deepened my expertise in search technology. Dive into the article to see how vector search and traditional keyword search can be used to bring the past into the digital age.
Read More »Last night, a spark of inspiration on my evening drive turned into a monumental achievement by the early hours: I successfully migrated 6,000 posts from Facebook to my brand-new Wordpress blog and later translated them to English and published at RaufAliev.com. So now I have two blogs, in Russian and English, having the same content as my Facebook (I don’t post anything on Facebook that isn’t meant for others to see, and I don’t write or say anything that I wouldn’t say publicly, so from a privacy perspective, everything is okay. Also, I don’t transfer comments to the posts, only the posts themselves.) This isn’t just about launching another blog; it’s about preserving years of shared memories and insights in a more accessible and enduring format.
I tackled the challenge of exporting and translating a vast archive of content, making it available not only in the original Russian on BeingInAmerica.com but now also in English for a global audience. This project was driven by my frustration with social media’s fleeting nature and the limitations in searching tagged posts.
Curious about how I managed to automate the complex process of syncing thousands of posts across languages and platforms? I’ll be sharing the behind-the-scenes story of the tools and technologies that made this possible.
Read More »Navigating the vast seas of product searches in B2B and B2C marketplaces can be quite a headache, especially with loads of data from various suppliers. It’s tough for marketplaces to tweak supplier info without spending a fortune, yet when searches go awry, customers tend to blame the marketplace, not the suppliers. My new article suggests a slick new way to cut through the clutter—think product families, not just standalone products. This isn’t just about tidying up; it’s about making the search experience smoother and more intuitive for everyone involved.
Let’s dive into why the old way of doing things—splitting catalogs into neat categories and individual products—just doesn’t cut it for big, diverse inventories. Take electronics and clothes: sorting shirts by color and size is straightforward, but try categorizing gadgets that way and you’re in for a real challenge. The game-changer here could be switching to a product families model, which groups related products together under one big family umbrella. This approach keeps things organized and makes shopping easier, which is exactly what we need for a smoother, more customer-friendly search process in our digital storefronts.
The Part I of this topic is about Product Families as an extension of the Variant Products concept.
Read More »