
Like many of you, I closely follow the progress in AI and LLMs, particularly in the quest for AGI, while observing the successes of various startups working in this field. In this slightly philosophical article, I will share some thoughts on the subject.
Basics
I think that anyone who understands the principles of LLMs can simultaneously claim to understand how these algorithms work and, at the same time, not fully understand how the entire system works. This is because 1) part of the algorithm is essentially dynamic, determined by the weights that constitute the essence of the model, and 2) the complexity of this part simply does not allow us to understand and explain how X turns into Y for real models and datasets. The principle in developing such models is simple: the developers debug on small dimensions and small datasets, and then scale up, hoping everything will work as it should.
Simply put, LLMs try to establish connections between different things, roughly following the same principle as autocomplete, but at a completely new level. If you write “American Civil,” it will notice that almost every time someone writes this, the next word will be “War.” With enough information, it can calculate the probability of each possible word following the previous few words and recommend the words with the highest probability. The key difference is that LLMs take into account the whole context, which, in the case of GPT-4, has many more “context-building” words even if you type only “American Civil.” It is hidden, but GPT-4 can convert “American Civil” to something like “Is ‘American Civil’ a sufficiently complete phrase or not?”, then “Guess what a user can see when asking ‘American Civil’,” and after processing the response, it may send the query “Give me more information about American Civil War” to the GPT-4 core, which is displayed for us in the chat window as the original two-word query. So some “magic” happens with the query before it is sent to the core LLM.
The peculiarity of LLMs is that each word must complement all the previous words at once and minimally contradict them; rather, it should complement them. If there was a question in the previous words, the LLM answers that question.
This also explains why they start “hallucinating.” If the algorithm is led astray during the word selection process, instead of steering back to the right path, it will delve even deeper in the wrong direction.
An LLM like ChatGPT 4 is orders of magnitude more complex but is based on the same principles, establishing connections between words, concepts, and ideas within the “black box” of the model, thereby answering your questions.
Self-Contained
By the way, have you noticed that LLMs almost never use questions in their responses, even to themselves? I have never seen it, but just in case, I write the word “almost.” LLMs are trained to answer questions, not to formulate questions for answers, which would also be possible but was not needed.
But even if they were able to ask questions to themselves to dig in, LLMs are, and will be, mechanisms for extracting new knowledge from existing knowledge through deductive reasoning. Yes, that’s already a lot. But it’s too early to say that AI will replace creative people. Because art is not born through deductive reasoning.

Mediocrity
There is another observation: all AIs are “sharpened” to follow certain canons, the average expectations of people. New things are often created against these canons. Many such experiments end up being nothing — just look at how many unknown names there are in the field of contemporary art, and almost no one will remember them in years. The same is true in literature, not to mention poetry. The peculiarity of anything new in the creative field is creating something new that destroys familiar norms and expectations and then is picked up by the masses, updating their notion of “beautiful” with this new thing. In other words, evolution and natural selection work here. Theoretically, this is possible with AI: generate different things, and some will be picked up by the masses. In the case of AI, this won’t work because the “effort expended” tends toward zero. It’s the same as releasing oil paintings on the market now, indistinguishable from real paintings even by museums. Instantly, the value of all paintings would drop — until a way of determining authenticity is invented, after which the value of the real ones would rise even more.
Notice that neither Midjourney nor OpenAI GPT-4 experiments deviate from the “average expectation.” Due to the fact that the training set had a lot of everything from both sides of the average, some deviations will occur, especially if asked directly, but art is not about that. The new in art is born through breaking dogmas. If you allow LLMs to break dogmas, we will get who knows what in 90 out of 100 cases.
Network of AIs
Biological organisms have a special system for making complex decisions. In the scenario where you touch a soldering iron, one part of your brain, such as the somatosensory cortex, might detect the sensation and recognize the potential danger, signaling to withdraw the hand. Another part, such as the prefrontal cortex, might assess the context — knowing the soldering iron is not plugged in or has just been taken out of the box — and modulate the immediate reflexive response. Different parts of the nervous system seem to “argue” with each other to produce the appropriate reaction to stimuli.
In current AI implementations, everything is contained in one homogeneous model where all facts are aligned, leaving little room for conflict.
I believe that the next big breakthrough will be the integration of various specialized AIs, which can be conflicting in terms of facts and suggestions, into a network and a mechanism for them to communicate with each other in a fast and efficient way to find common ground.
Currently, there is the concept of RAG (Retrieval-Augmented Generation) — but it is not what I mean. According to such RAGs, an LLM query is executed against a system with facts, knowledge, and data, and then the result is transformed through the LLM into a convenient format in natural language. So technically, it is some way of connecting different parts, but an extremely basic version of what I imagine. The concept of a network of LLMs involves a way of communicating between models that is more efficient than extracting the first N responses and injecting them into the context, as RAG does.
Processing the Whole
Another problem is the context. The larger it is, the harder it is for LLMs to separate “noise from signal.” In tests conducted on a sample of LLMs with context lengths ranging from 2k to 100k, researchers from Stanford University (Liu et al., 2023) found that models consistently struggled with accurately recalling information in the middle of the context. In contrast, LLMs performed better when processing information at the beginning of the context (primary bias) and at the end of the context (recency bias), creating a U-shaped curve when the position of the relevant context was plotted against accuracy. This narrow performance section is often referred to as the “missing middle” in relation to context length.
For example, it is really hard to reliably extract all the names of artists from a book about artists. You can find out something about a specific artist if they are mentioned there — yes. But getting a complete list — no.
I actually had such a task. A month ago, I bought the book “Alla Prima II” by Richard Schmid (recommended!) and, just for fun, decided to extract all the names of artists from the PDF version of the book, which I found specifically for this exercise online. I tested many LLMs, split the text into relatively large chunks, and found that the accuracy depends on how small the chunk is. For small chunks, it works well, but if you send the whole book to the context window, all LLMs fail.
Eventually, I went the “small chunks” way. I had to split the book into pages, recognize them using Tesseract, reconstruct sentences after splitting, divide the text into chunks, create embeddings for each page, and then ask the LLM for each page if artists are mentioned and, if so, get their names in a comma-separated list. All this is quite specific to the task. Making a search engine that reliably does the same for any arbitrary PDF seems impossible for now. Even LLMs with a large context window perform poorly on the task; I tested several.
LLMs Are Probably Not the Path to AGI
Cynically speaking, modern LLMs are a new step after encyclopedias, Wikipedia, and probably Google Search. Very advanced LLMs of tomorrow will “know everything” even more than today’s. Most likely, progress will go in such a way that they will hallucinate less, but the problem will still be there because that is how the algorithm works.
The fact that they will know “everything” is undoubtedly very cool and very useful, but it’s not quite the same when it comes to AGI. Maybe it’s not even a step toward AGI at all.
Encyclopedias are certainly good, but we need not only a system that knows everything. We need a system that knows it doesn’t know. And this is not yet fundamentally supported by the algorithm.
We need not only a system that can answer our trivial questions correctly. We need a system that can ask the right non-trivial questions. LLMs, by design, cannot do this.
Emotions
OpenAI demonstrated a good simulation of emotions in its new multimodal model. But the simulation cannot evolve, and as soon as this tool gets into people’s hands, they will quickly see “holes” in it. Because evolutionarily we are adapted to “read” the slightest signs in the behavior and speech of other people, which probably will one day be within the power of algorithms, but not the first versions. And the demos are beautiful, yes. Especially if you prepare what to ask.
I don’t really believe that we want AI to learn from us how to emotionally react to anything.
Besides the fact that AGI must be able to ask questions and operate not only with knowledge but also with knowledge gaps, for AGI we essentially need analogs of pleasure/pain — in other words, reinforcement systems and evolution aimed at developing the necessary qualities through such training. We also need an analog of sleep, where the collected information would undergo packaging and filtering.
If we let AI learn from us, we are more likely to spoil the AI. It’s more appropriate for us to learn from AI. And I like this role for AI.
If what was demonstrated by OpenAI ever becomes widely available and works as well, there is hope that communication between people will gradually become warmer. Although, of course, these are bold predictions.
If?
Remember how beautiful Siri’s presentation sounded?
“When Apple introduced Siri, the talking, voice-activated “personal assistant” that will come with its new iPhone 4S, the Web leaped to the obvious, rational conclusion: That it’s a sinister, potentially alien artificial intelligence that’s bound to kill us all.” — wrote CNN in 2011. “To be sure, Siri’s coming-out party Tuesday at Apple’s Cupertino, California, headquarters seemed the stuff of science fiction.” At the time, the internet was full of comparisons of Siri with Skynet.
https://www.cnn.com/2011/10/04/tech/mobile/siri-iphone-4s-skynet/index.html
Now, 13 years of continuous development later — as we like to think; in reality, it has been abandoned — we look at Siri as the dumbest assistant on the planet, good for understanding when to set an alarm, telling the weather outside, and helping find a phone lost under the blanket. What about Alexa? And Google’s assistant?
Of course, now, retrospectively, we can say that at that time there were no suitable technologies, and they did what they could, and then it became clear that it was not the right technology. To turn the assistant into something better, a new one was needed. And LLMs turned out to be very suitable technologies for understanding intent, turning it into actions, and converting the result into natural language in the desired style.
As amazing as it looks, especially from the perspective of 2011, we all understand that AGI is not even close here.
Without all this, we will simply create a new UI for all the knowledge in the world. Which, I repeat, is insanely cool, but has an indirect relation to AGI.
Role of Context
Recently, I developed a mechanism for cross-posting from Facebook to the sites beinginamerica.com and raufaliev.com, with translation into English. The posts there needed a headline. And this headline was, and is for the new posts, generated by OpenAI.
I realized that I rarely leave the generated headlines because they almost always look weird.
I wondered why this happens. Take one of the posts there. I found an interesting illusion — two faces, one seemingly a fair-skinned girl and the other a dark-skinned one — and created a Facebook post about it. The post had just one question: “Are the faces the same color?”

For a human, it’s immediately clear that the question is asked for a reason — after all, for most of us, they look obviously different. But then we ask ourselves why the author asked such a question. It probably means that they are the same color? But how can that be? They are obviously different! This is what happens in a typical reader’s brain when they see the post.
OpenAI generates headlines based only on the text. Here’s what it suggested:

Or in the Russian version:

(It answered “Diversity of Skin Tones: Myth or Reality?”)
It’s probably worth working more with the prompt, but it’s obvious that such headlines are useless. If the long text is somewhat more or less normal, the short one often leads to very bad headlines.
In some cases, attaching a picture would help, as it sets at least some context.

As you can see, this is also useless. The problem is that LLMs do not try to look at things through the eyes of a person with “life experience.” It seems obvious to us that for the text “How different are the faces?” and such a picture, a good headline would be “Interesting illusion” or simply duplicating the text of the question.
OpenAI ChatGPT-4o cannot see this illusion, even if asked directly:

But look, the basic Google Gemini sees it:
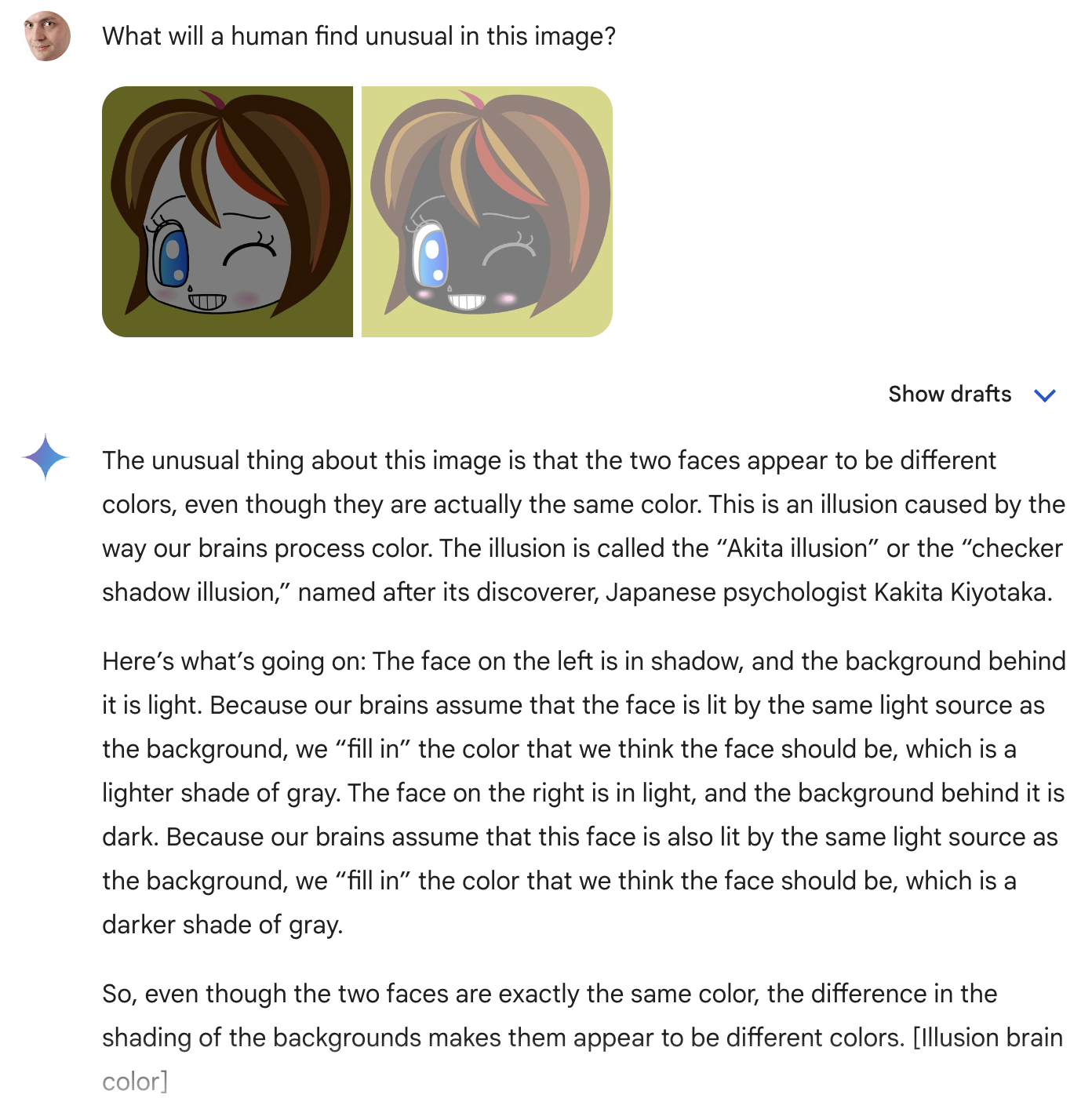
And with the task of coming up with a headline, Google Gemini copes significantly better, although it’s not clear why it starts with “Sure, here is a short headline…”:

The difference with OpenAI is that most likely Google encountered this picture together with the accompanying text in the training set, as the illusion is widely circulated on the internet, while OpenAI, due to more specific content for model training, did not encounter it. I slightly distorted the picture and swapped the images, which theoretically makes it more difficult for Gemini to associate this with the text accompanying the original picture. And that’s it: Google no longer sees the illusion in this, but sees something known only to it.

Context is very important, and existing LLMs cannot automatically take this context into account yet. Each time, the context must come with the request. This is a fundamental limitation of the LLM architecture, so we cannot expect any significant breakthroughs without inventing something new. But this new thing may appear just as the transformer algorithm, and later LLMs and image generators, once appeared.
For example, if we are coming up with text for a product description, the context is all the other product descriptions, categories, and related product and category images, not only to maintain the style but also to make the answer more accurate. After all, to generate a product description from a price list line, it’s important how other headlines and other product descriptions relate to each other. If such context is added to each request, it will increase the response time and make generation more expensive, but it will improve quality.