I found a way to speed up the data import in hybris. The approach explained below will allow you to import data
two times faster than the regular Impex does. Video of PoC, some numbers, and technical details are below.
Hybris importing capabilities overview
There are two main ways in hybris to update data from the external sources:
- IMPEX.
and
are also in this category, because Spring Integration and Import Cockpit convert CSVs to IMPEXes.
- hybris API (modelService). This approach is to create your own importers with the custom logic.
Perhaps, in hybris 6.0 SAP introduced ServiceLayer Direct as a projected replacement for the legacy JALO layer. However, the new engine
has not become the default engine in 6.0/6.1 due to the amount of crucial legacy business logic working only with Jalo. I leveraged some of its components to work with the objects which meet the criteria of new engine compatibility.
Such objects as StockLevel and PriceRow are common key players in the integration process. If your prices or availability data are regional-specific or store-specific, the amount of data could become really massive.
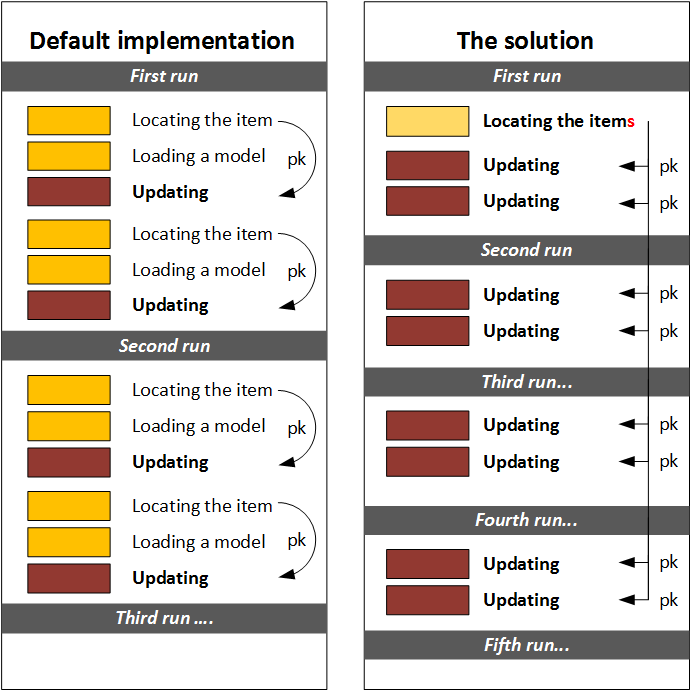
For both mentioned methods, for the data update, hybris makes three sequential requests:
- Locating the item applying the filters. For example, warehouse and product for the StockLevel object. Example of the Flexible Search request for this step:
SELECT {pk}
FROM {StockLevel}
WHERE ( {StockLevel.warehouse} = 8796194146261
AND {StockLevel.ProductCode} = 'LProduct_1' )
- Loading the model into memory by pk received at the previous step. The corresponding FlexibleSearch request:
SELECT *
FROM {StockLevel}
WHERE ( {pk} = 8807037634519 )
- Updating the model with the data received from the external system. The SQL update statement:
UPDATE stocklevels
SET hjmpTS = 1 ,
modifiedTS='2016-09-23 12:05:47.543',
p_available=11021
WHERE
PK = 8807037634519
First two operations (Locating and Loading) use the cached data if there are any (region cache). However, it doesn’t solve the problem completely: if you have millions of the items to change, 2/3 of your operations will take precious time, memory and CPU resources.
The solution
The idea of the solution is to get rid of the first two requests and use the pre-build memory lookup tables instead.
Will it work? Tests shows that it is working twice faster than the regular Impex import:
|
number of items |
average creation time |
average update
time |
|
| Regular Impex import,
16 threads |
50000 |
19,6 sec |
14.8 sec |
|
| ServiceLayer Direct Import
16 threads |
50000 |
17,1 sec |
7.5 sec |
two times faster! |
You can see the difference in the JDBC log:
| Impex Import |
ServiceLayer Direct |
There are all three components marked by color (Lookup, Loading model, Updating)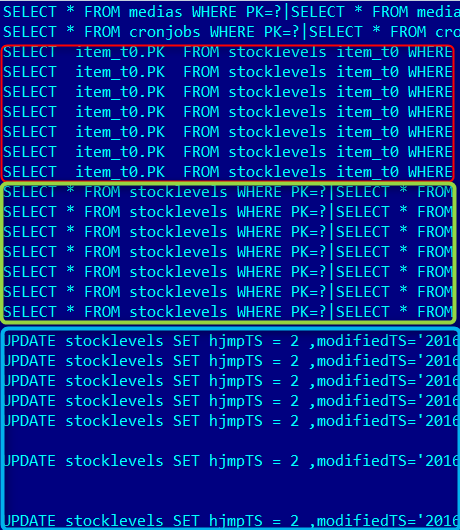 |
There is only one component, an Update statement.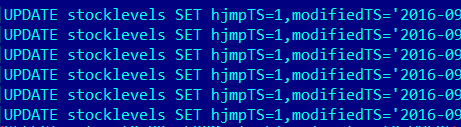 |
Technical details
- Multithreading is not implemented in hybris classes. You need to manage it by yourself.
- There are three objects, UpdateRecord, InsertRecord and DeleteRecord. The example below is about UpdateRecord, all others are used in the similar way. I used StockLevel as an example, you can change it to other objects. There are some limitations, see the next section for the details.
UpdateRecord updateRecord1 = new UpdateRecord(
pk,
"StockLevel",
version,
Sets.newHashSet(
new PropertyHolder("available", availableValue),
new PropertyHolder("overselling", oversellingValue)
)
);
changeSet.add(updateRecord1);
DefaultWritePersistenceGateway defaultWritePersistenceGateway =
Registry.getApplicationContext().getBean("defaultWritePersistenceGateway",
DefaultWritePersistenceGateway.class)
CacheInvalidator cacheInvalidator =
Registry.getApplicationContext().getBean("cacheInvalidator",
CacheInvalidator.class);
final Collection<PersistResult> persistResults =
defaultWritePersistenceGateway.persist(changeSet);
cacheInvalidator.invalidate(persistResults);
In order to create objects (CreateRecord), you need to generate PKs. The next example shows the details:
TypeInfoMap persistenceInfo = Registry.getCurrentTenant().getPersistenceManager().getPersistenceInfo("StockLevel");
PK pk = PK.createCounterPK(persistenceInfo.getItemTypeCode());
Drawbacks and limitations
No one will give you anything in this life 😉 The downside of this approach is in the following points:
- There are some limitations about the types managed by SLD. According to the hybris documentation, in the following cases, you cannot use ServiceLayer Direct:
- Item attribute is configured as Jalo in items.xml. It means there is a business logic in a Jalo class (Item or Manager) for a getter or setter.
- Item attribute is configured as a property in items.xml but it has an overridden getter or setter in a Jalo class
- Item has a custom logic in createItem(…) protected method (usually for validation or preparation purposes)
- As to this particular architecture,
- You lose all flexibility that the regular impex import has.
- If you need to reference to any other objects (like warehouses), you need to perform additional requests to build a map (WarehouseId -> PK).
- You need to write more code and test it thoroughly.
Video
© Rauf Aliev, September 2016

Igor Sokolov
26 September 2016 at 18:18
Hey Rauf, there is a third option: we integrated into hybris Sping Batch which relies on the plain data source and can process information in transaction frames for example by 100 object at once. Also it provides wide capabilities to create a complicated sequence of step for handling which full of control when something goes wrong. The last thing was nice especially if you spent much time with explaining to custom how they should read errors after ImpEx.
Rauf Aliev
28 September 2016 at 09:51
Thank you! Good comment. I will find time to investigate it. For the first part of your message, regarding spring batch, were you creating our updating data? For the update, you will have three requests any way, because it’s a way how hybris persistence works.