Cluster and Conquer: Product Families in Search and Navigation

For large B2C and B2B marketplaces, searching for individual products, especially when the information comes from independent suppliers, is a very challenging task. Marketplaces cannot always influence what comes from suppliers, and when they can, it is quite expensive to do so with large volumes of products, and such costs are not always justified. However, if the search function is poor, it is typically associated with the marketplace, not with the suppliers’ inadequate product descriptions.
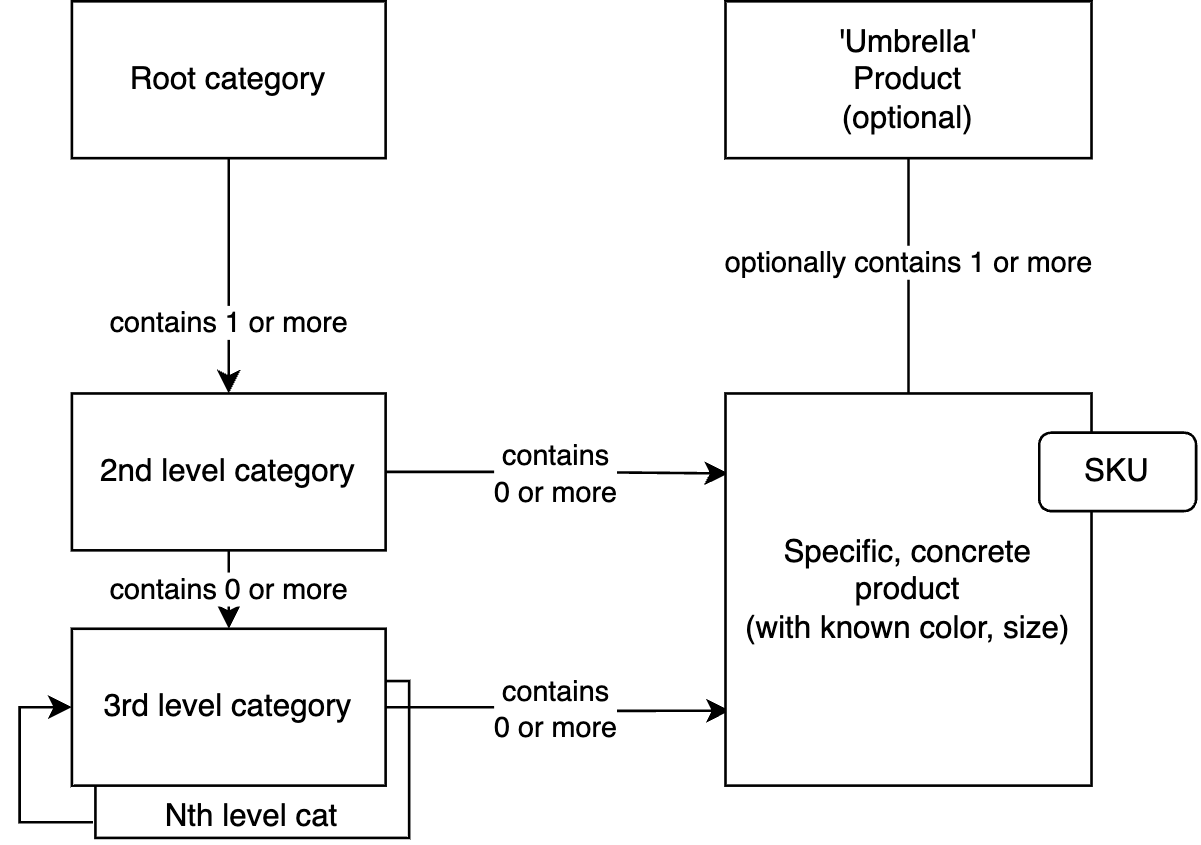
The typical hierarchy of a product catalog contains two district groups: categories and products, while the products often have a base product and variant products.
As to base and variant products, this concept doesn’t work well for large catalogs with diverse items that have variations difficult to categorize simply. For example, for clothing, a simple classification might be color and size. But for electronics, it’s much more complicated. Almost every type of product has its variations. And if your store carries both electronics and clothing in one catalog, simple solutions do not work at all.
So, base and variant products have very specific implementation options in SAP Commerce, and just not to confuse with those, let’s use product families, and separate specific, concrete products having an SKU and an ‘umbrella’ product representing a product family. Such organization covers both the base and variant products as it is in many e-commerce stores, and a new concept of product families I am explaining below in detail.
To display only base products with a list of available variants, SAP Commerce has a feature called “variant grouping”. It also has a setting, facet grouping — if enabled (by default, it is not), facets are computed for each group. If not they are computed for each specific (variant) product. It works well if the variants have one variant attribute, such as style, color, or size. Of course, as anything in SAP Commerce, the behavior can be changed via customization.
So, the best practice now is considered to be grouping variants in search results. But very often, especially in marketplaces, covering a wide range of products through the baseProduct-variantProduct relationship is very challenging. This significantly increases the complexity of the catalog and complicates maintenance and development. In SAP Commerce, there is also the concept of multi-dimensional products, which allows for the construction of complex variant products, but still, it is assumed that the structure for the entire catalog will be the same and generally not complicated.
I think that for large catalogs, it is necessary to introduce additional grouping of products. The easiest way to introduce this grouping is through tagging. In general, this is similar to categories, but unlike categories, the list of tags is flat, and this list is not managed separately. Products that have the same tags are grouped together, and the rules for which tags are selected for which queries can be part of the search configuration.
Such tags can also be assigned to products based on rules that can be automated or manual. In one of my previous projects, such a system was implemented and performed well even when the number of rules reached hundreds.
I explained this concept in my article from 2016, Product Design for Variants. It was called “Product Family” Technically, if you assign more than one product family to a product, you basically get the same as tagging provides.

To a tag, or product family, you could assign a special type of product that is displayed in search results in the same way a base product is displayed in the search results as explained above, but the name and image of the group product would reflect what is common among all products marked with this tag or product family. The page of such a product is essentially a variation of the category page.
A great example of product families shines with customizable phone cases. Consider a phone case store offering various designs, materials, and functionalities. They could create product families like:
- “Clear_case”: This family groups all transparent cases, regardless of design or features.
- “Impact_resistant”: This family focuses on cases with high protection against drops and bumps.
- “Wallet_case”: This family features cases with built-in card slots for convenience.
- “Fan_art”: This groups cases showcasing designs from popular franchises or artists.
- “Minimalist”: This family emphasizes simple, elegant designs without unnecessary elements.
Each phone case could belong to multiple product families, reflecting its different appeals to customers. This allows shoppers to easily find cases that match their desired aesthetics, functionality, and fandom, all within a well-organized structure without excessive categories.
The product families themselves are searchable — like “clear case” can be found by “transparent case” as well.
Basically, product families play a role of categories, but these categories are only partly navigational. They are not part of the main menu but have a dedicated page that makes them discoverable via Google search. Additionally, products from the same family are navigationally connected on the product pages.
It is particularly important to consider whether adding a facettable product characteristic might introduce unnecessary complexity and create unwanted side effects. The key word here is facettable. The non-facettable characteristic can be easily added without any consequences. If only five out of 1,000 products have variations in some characteristic—such as “shape”—it would be excessive to introduce a new characteristic just to distinguish these five variants from each other.
With LLM, such grouping as well as generating metadata for such products can be automated.
But how do you teach Solr to determine a category or product family by a query?
Here, I refer you to my recent article about Search monitoring. It’s a great task for a data science team, and it’s relatively straightforward. You see, you already have a lot of queries and an understanding of which products are clicked on based on these queries, and the products belong to categories/product families. That is, you can link a set of keywords with a category or product family and train the service to predict which keywords to choose for which category or product family.
The technical details for implementing such a solution can be organized into several key phases:
- data collection,
- data preprocessing,
- model training.
Data collection implies precisely the gathering of information on which products (associated with categories) were accessed based on which queries. These logs can be stored in a scalable and query-efficient data storage system like Amazon Redshift or Google BigQuery.
Data preprocessing involves cleaning and structuring the data for analysis. This includes filtering out irrelevant queries or noise, such as automated bot queries.
For model training, you might consider a supervised learning approach where the input is the keywords from the queries, and the output is the product categories or product families. A variety of machine learning models could be used.
Considering the usage of word embeddings such as Word2Vec could enrich the model’s understanding by incorporating semantic meaning of words. These embeddings can transform text data into numerical data that machine learning models can process.
For a data scientist, the task is pretty straightforward. There is no need to integrate the machine learning mechanisms with your backend (although it would be a good idea too) — you can prepare a big set of rules and store them in the Solr core.
This simpler alternative, a statistical approach, is often a working shortcut to test the idea. Just open a dedicated Solr core(s) with the collected information (document key:category tags->searchable value:list of queries, keywords + document key: category -> searchable value:category tags) and provide the most relevant category based on the search keyword match. Compared with the machine learning approach, this one is faster, but the accuracy might be a compromise.
Additionally, you may involve some hints about the previous user interaction with the website to determine a category or product family more accurately — especially if it works well with the B2B websites. If a customer primarily uses 2-3 categories from your catalog, this information may be taken into account as well to re-rank the results.
Dynamic Nature of Product Families
The fact that products are organized into product families based on rules allows for the automatic grouping of a product simply based on rule activation. For example, if the rule states that phone cases with anime-style prints can be reliably found using the keywords “anime” plus a filter for the product type “phone case,” then all such cases will be organized into a group, which can serve as something like a dynamic category. If you open the page of any product from this category, other products from the same group can be displayed somewhere on the page if they are available.

Some products may not have the word “anime” in their name or description, but they are obviously about anime. As soon as this is discovered, the administrator expands the rule with an additional condition.
For example, the name of one of the products above, “Phone case Sanji Luffy Zoro iPhone Case”, indicates that the phone case belongs to the anime group primarily through the mention of “Sanji,” “Luffy,” and “Zoro.” These names are associated with well-known characters from the popular anime series “One Piece.” created by Eiichiro Oda. This association makes it clear that the phone case features themes or artwork related to “One Piece” and, by extension, falls into the broader category of anime-related merchandise.
The complexity arises when rules become complicated and can potentially cause false positives. To timely notice this, it is sufficient to build a report on the changes in each product family, and also to save in the product data the rule that linked this product to the product family. If a product falls into a product family, it is included in the report. A second occurrence in the report will not be included again. If a product is removed from a product family due to a rule change, it is also included in the report. Overall, even for a large catalog, such reports are relatively easy to review on a regular basis—primarily because the report only reflects changes.
As a result, cases with names including Zoro, Luffy, or Sanji will begin to be found under the query “anime iPhone cases.” Similarly, cases compatible with the iPhone 14 will start being discovered under “iPhone 14.” Combined queries like “anime iPhone 14 case” will bring up the product Phone Case Sanji Luffy Zoro iPhone 14 Case because it is linked to two product families, “anime cases” and “iPhone 14 cases.” Additionally, Google will index the anime cases page and direct customers there. You have to admit, this is great.

Comments are closed, but trackbacks and pingbacks are open.