

Today I want to talk about tailoring website search functionality for Chinese and Japanese languages.
When it comes to entering “the East”, companies often face many challenges they could not have experienced before. Everything is different in China and Japan including the way how websites are built and how the users interact with them. In this article, I will cover one aspect of these challenges: how to adapt product/content search to work with Japanese and Chinese languages.
Before I start, I’d like to say a lot of thanks to my co-authors who helped me go through the linguistic quirks and idiosyncrasies, revise and extend this writing, and eventually having me come off looking like a pro. Thanks to Timofey Klyubin who is a guru in Japanese, and Dmitry Antonov who gave me valuable feedback, great tips, and pointers on Chinese.
Table of Contents
- Introduction
- Language Detection
- Language Variants
- Character Variants
- Conversion Between the Systems
- Word Segmentation
- Word Normalization
- Numerals
- Synonyms
- Homophones
- Search by Pronunciation
- Punctuation marks
- Search UI observations
- Recommendations
Introduction {#Introduction}
There are three languages traditionally considered together in the context of information retrieval, internationalization, and localization. These languages are Chinese, Japanese, and Korean. Their writing systems are based entirely or partly on Chinese characters.
This research can be useful for the internationalization, localization and information retrieval components and projects. Internationalization is mainly about support for multiple languages and cultures. Localization stands for adaptation of language, content, and design to specific countries, regions, or cultures. Cross-lingual information retrieval deals with documents in one or more different languages, and the techniques for indexing, searching, and retrieving information from large multi-language collections.
From the perspective of information retrieval, the Chinese and Japanese present numerous challenges. The major issue is their highly irregular orthography and language variants. In this article, I collected the most important ones we need to take into account when implementing the language-aware full text search as well as how to address them.
Language Detection
When and where possible, the website should allow the user to specify unambiguously what language is going to be used for entering a search query and presenting the results. Normally, the users enter search queries in the same language as the website’s interface is set to.
However, our observations show that the customers use their native language if the website is advertised in their country even if the localized version of the website is not pre-selected, automatically or manually. If the first-level domain is from the local pool (.cn for China or .jp for Japan), the user’s intent of using the native language is even stronger. To address this case, there are AI and statistical techniques to determine the likely language.
The automatic language detection is a very challenging task especially if the analyzed string is short. For example, if it is has a mix of Latin and Chinese characters from Japanese Kanji set may indicate that the text is either in Japanese or Chinese which can be too abstract.
Language variants: Dialects {#Dialects}
There are many more dialects in Chinese than Japanese. Both full of specificities interesting to us in regard to the topic.
The thing is Chinese is not a single language, it is a family of spoken languages. China has a lot of dialects, but the most popular is Mandarin (or “Standard Chinese”, over 1 billion speakers) and Cantonese (or Yue, over 100 million of speakers).
In Japan, there are two major types of the Japanese language: the Tokyo-type (or Eastern) and the Kyoto-Osaka type (or Western). The form that is considered the standard is called “Standard Japanese”. Unlike Traditional and Simplified Chinese, the standard Japanese has become prevalent nationwide.
Language Variants: Scripts {#Scripts}
Japanese: Kana and Kanji
There are two typical Japanese scripts, Kana and Kanji.
- Kanji is logographic Chinese scripts, Chinese characters adapted to write Japanese words. There are thousands of kanji in Japanese
- Kana is a collective term for Japanese syllabaries, Hiragana (46 characters) and Katakana (48 characters). They are derived by simplifying Chinese characters selected to represent syllables of Japanese.
The same Japanese word can be written in either kana or kanji:
| English word | Japanese (Kanji) | Japanese (Katakana) | Japanese (Hiragana) |
|---|---|---|---|
| fox | 狐 | キツネ | きつね |
This complexity is also illustrated by the sentence 金の卵を産む鶏 (“A hen that lays golden eggs”). The word ‘egg’ has four variants (卵, 玉子, たまご, タマゴ), ‘chicken’ has three (鶏, にわとり, ニワトリ) and ‘giving birth to’ has two (産む, 生む), which expands to 24 permutations. In many contexts only one option is correct.
Japanese has a large number of loan words or gairaigo. The considerable portion of them is derived from English. In written Japanese, gairaigos are usually written in katakana. Many gairaigos have native equivalents in Japanese. Sometimes a Japanese person can use either a native form or its English equivalent written in katakana. This is especially the case of proper names or science terms. If you are not familiar with the native variant, you will probably use a syllabic construct.
Some examples:
| English word | Japanese (native word) | Japanese (English loan word) |
|---|---|---|
| door | 扉 /tobira/, 戸 /to/ |
ドア /doa/ |
| mobile phone/cell phone | 携帯 /keitai/ – “mobile phone”, “handheld”, 携帯電話 /keitaidenwa/ – “mobile phone” |
モバイルフォン /mobairufon/ セルラー電話 /serurā denwa/ |
School kids use hiragana more commonly since they might not have learned the kanji equivalents yet.
Additionally, there is Romaji which uses Latin script to represent Japanese.
Chinese: Traditional and Simplified
Along with the sheer complexity and size of the character set, Chinese has several related language variants. In Taiwan, Hong Kong, and Macao, Traditional Chinese characters are predominant over the Simplified Chinese variant which is used mainly in Mainland China, Singapore, and Malaysia.
Some traditional Chinese characters, or derivatives of them, are also found in Japanese writing. So there is a subset of characters common for different languages. These shared Chinese, Japanese, and Korean characters constitute a set named CJK Unified Ideographs. It is huge: the CJK part of Unicode defines a total of 87,887 characters. The characters needed for everyday use by the users is much smaller.
For the search, queries can be in either traditional or simplified characters or a combination of the two; search results should contain all matching resources, whether traditional or simplified.
Below is a random text to demonstrate the differences between the writing systems. Characters highlighted by yellow marker have different spelling in Simplified (输入简体字点下面繁体字按钮进行在线转换) and Traditional (輸入簡體字點下面繁體字按鈕進行在線轉換) Chinese.

Character variants {#CharacterVariants}
Chinese and Japanese characters don’t use upper or lower cases. They have only a single representation independent of context.
The majority of letters are monospaced.
There are no additional decorations for the letters as it is in Arabic, for example.
Conversion between the systems {#Conversion}
The conversion is important when either a user or a document use a mix of Chinese writing systems. For example, Given a user query 舊小說 (‘old fiction’ in Traditional Chinese), the results should include matches for 舊小說 (traditional) and 旧小说 (simplified characters for ‘old fiction’). That means that conversion should be done at the query level.
The accurate conversion between Simplified Chinese and Traditional Chinese, a deceptively simple but in fact extremely difficult computational task. If your search is used by millions, the system will be much more resource-intensive comparing with the setup for the European languages.
There are three methods of conversion:
- Code conversion (codepoint-to-codepoint). This method is based on the mapping table and considered as the most unreliable because of the numerous one-to-many mappings (in both directions). The rate of conversion failure is unacceptably high.
- Orthographic conversion. In this method, the meaningful linguistic units, especially compounds and phrases, are considered. Orthographic mapping tables enable conversion on the word or phrase level rather than the codepoint level. An excellent example is the Chinese word “computer.” (see examples below).
- Lexemic conversion. A more sophisticated, and more challenging, approach to conversion. In this method, the mapping table contains lexemes that are semantically, rather than orthographically, equivalent. This is similar to the difference between lorry in British English and truck in American English. The complexity of this method in lexemic differences between Simplified and Traditional Chinese, especially in technical terms and proper nouns.
| Simplified Chinese | Traditional Chinese | Translation |
|---|---|---|
| 干 | 幹 or 乾 or 榦 | (dry, make, surname) |
| 电话 | 電話 | (telephone) |
| 软件 | 軟體 (Taiwan) | (software) |
| 计算机 (“calculating machine”) | 電脳 (“electronic brain”) | (computer) |
In Japanese, the kanji characters may or may not have the same-looking Chinese character.
| Chinese (Simplified) | Chinese (Traditional) | Japanese | Japanese | Translation |
|---|---|---|---|---|
| 两 | 兩 | 両 | (both) | |
| 龟 | 龜 | 亀 | カメ | (tortoise) |
It is generally believed that the top priority for Chinese discovery improvements is to equate Traditional characters with simplified characters. For Japanese, there is also a problem of equating Modern Kanji characters with Traditional Kanji characters, but it is not so strong as it is in Chinese where you deal with two different scripts. There is a priority for Japanese discovery improvements to equate all scripts used in the language: Kanji, Hiragana, Katakana, and Romaji.
In Apache Solr, the only other relevant ICU script translation is a mapping between Hiragana and Katakana. This is a straightforward one-to-one character mapping working in both directions.
(Here I mentioned Apache Solr for the first time. For those who are not familiar with Solr, it is one of the most comprehensive opensource search engines. SAP Commerce Cloud uses Apache Solr for product and content search. One of the goals of this article is to give recommendations on how to configure Solr properly for Chinese and Japanese search)
Consider making Simplified Chinese and traditional Chinese inter-searchable. If one searches for 计算机 (computer, Simplified) or 電脳 (computer, Traditional) , the results should contain the records with both 计算机 and 電脳. At least measure how often each of these writing systems is used by your customers to make an educated decision on how to make search better.
Word segmentation {#WordSegmentation}
Chinese and Japanese are written in a style that does not delimit word boundaries. Typical Chinese sentences include only Chinese characters, along with a select few punctuation marks and symbols. Typical Japanese sentences include mostly Japanese kana and some adopted Chinese characters that are used in the Japanese writing system. So, how does one decide how to break up the words when there are no separators in between?
As for spaces, they delineate words inconsistently and with variation among writers. Formally, there must always be a space between English words and Chinese words, but in fact this rule is not strict and many neglect it. There is no space between the Arabic numbers and Chinese characters.
Coming back to word segmentation, there are different approaches for splitting the text into the word units. The most common algorithms use dictionaries and, additionally, a set of rules. This topic is still an area of considerable research among the machine learning community. All of these are not perfect: this segmentation cannot be done unambiguously, but different methods show acceptable results for the specific areas. For example, for scientific texts, the dictionary-based methods may show poorer results than the statistical or machine-learning.
For example, the word “中华人民共和国” (People’s Republic of China) is seven characters long and has smaller words within: “人民” (people) and “共和国” (republic country). The first two characters,“中华” are usually not be used as a word independently in modern Chinese, though it can be used as a word in ancient Chinese. Digging further, within the word “人民” (people), “人” is a word (human), but “民” (civilian or folk) is not a standalone word. These components can be organized in the hierarchy. As another example, while the proper segmentation of “中华人民共和国外交部” (Ministry of Foreign Affairs of the PRC) is “中华人民共和国 / 外交 部”, another word, “国外” (overseas), could also be erroneously extracted. Consequently, a search for “国 外” should most likely not match the string “中华人民共和国外交部” but a query for “外 交部” should.
A group of characters might be segmented in different ways resulting in different meanings. For example, In Japanese, the compound 造船所 (shipyard) consists of the word 造船 (‘shipbuilding’, 造 is ‘to make, build’ and 船 is ‘a ship’) followed by the suffix 所 which is ‘a place’. In Chinese, the situation is completely the same. There are Chinese jokes based on these ambiguities. Teahan in its “A compression-based algorithm for Chinese word segmentation” illustrates this with the following funny example:
| A sentence in Chinese | 我喜欢新西兰花 | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Interpretation #1 |
|
||||||||
| Interpretation #2 |
|
(This situation happens only in speaking language. A Chinese writer will use separator 的 to clarify what he means. 我喜欢新的西兰花 for the case 1 And 我喜欢新西兰的花 for the case 2)
The next example illustrates what happens when each character in a query is treated as a single-character word. The intended query is “physics” or “physicist.” The first character returns documents about such things as “evidence,” “products,” “body,” “image,” “prices”; while the second returns documents about “theory,” “barber,” and so on.
| 物理学 means | 物 means | 理 means | 学 means |
|---|---|---|---|
| Physics | Physics Evidence Products Price Body Image |
Theory Barber Science Reason Understand … |
School Study Subject School |
It creates a lot of irrelevant documents causing the precision of information retrieval to decrease greatly.
So, the challenge is how to extract the meaningful units of knowledge from the text for indexing to return better results at the query phase.
There are three approaches on how to perform text segmentation for indexing and querying:
- Unigrams: treat individual Chinese characters as tokens
- Bigrams: treat overlapping groups of two adjacent Chinese characters as tokens
- By part of speech or meaningful words: performs word segmentation and indexes word units as tokens.
For example, for the string “我是中国人” (“I’m a Chinese”),
| Unigrams | Bigrams | Word segmentation | |
|---|---|---|---|
| Token 1 | 我 | 我是 | 我 (“I”) |
| Token 2 | 是 | 是中 | 是 (“right”) |
| Token 3 | 中 | 中国 | 中国 (“China”) |
| Token 4 | 国 | 国人 | 人 (“man”) |
| Token 5 | 人 |
For the string “私は日本人です” (“I’m Japanese”),
| Word segmentation | Meaning | |
|---|---|---|
| Token 1 | 私 | “I” |
| Token 2 | は | (particle) |
| Token 3 | 日本人 | “Japanese” |
| Token 4 | です | “am” |
The third approach is the most challenging. How to extract word units efficiently?
The simplest method is dictionary-based. This is called the maximum forward match heuristic. Given a dictionary of frequently used Chinese words, an input string and the indexing text are compared with words in the dictionary to find the one that matches the greatest number of characters. The alternative approach is maximum backward match heuristic when the text scanned in the backward direction. This method is not accurate enough and creates a lot of false matches.
The alternative method is statistical. This method concentrates on two-character words (because two-character is the most common word length in Chinese) and detects the words based on the frequency of characters and bigrams.
In order to improve the process, there are a lot of other methods too. These methods are based on probabilistic automata and machine learning.
The best and the most universal of these methods are included in Apache Solr, and being part of Solr, in SAP Commerce Cloud as well.
Solr supports various methods of word segmentation both for Chinese and Japanese. Each method treats the text differently.
Chinese: Tokenizers for Apache Solr (and SAP Commerce Cloud) {#ChineseTokenizers}
For Chinese,
- Standard Analyzer is based on unigram indexing
- ChineseAnalyzer index unigrams,
- CJKAnalyzer indexes bigrams,
- SmartChineseAnalyzer indexes words based on dictionary and heuristics. It only deals with Simplified Chinese.
- HanLPTokenizer (https://github.com/hankcs/hanlp-lucene-plugin, http://www.hankcs.com/)
- Paoding (https://stanbol.apache.org/docs/trunk/components/enhancer/nlp/paoding) – possibly, it has issues with the latest versions of Apache Solr.
Let’s have a look at how the analyzers split the “我喜欢新西兰花” (from the example above) into terms.
Chinese: CJKAnalyzer {#CJKAnalyzer}
This analyzer has a simple bigram tokenizer. This is the fastest option, but the search recall will be the worst.
Bigramming doesn’t require any linguistic resources such as dictionaries or statistical tables. Every overlapping two-character sequence is placed into the index. Many bigrams are real words in Chinese and Japanese that may skew the results if the characters from the different words are combined together in the index. There is a common practice is to index Chinese texts simultaneously as words and as overlapping bigrams. The methods can be combined in a weighted fashion to improve accuracy.

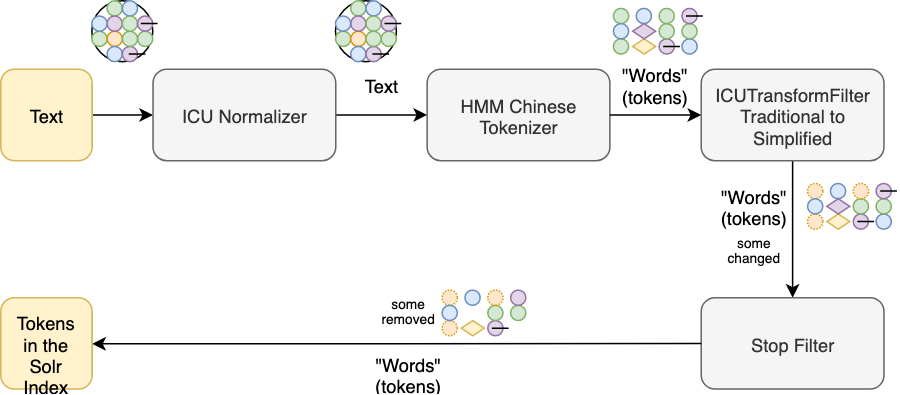
Chinese: SmartChineseAnalyzer
This analyzer has ***HMMChineseTokenizer ***which uses probabilistic knowledge to find the optimal word segmentation for Simplified Chinese text. The text is first broken into sentences, then each sentence is segmented into words.
Segmentation is based upon the Hidden Markov Model.
A large training corpus was used to calculate Chinese word frequency probability.
This analyzer requires a dictionary to provide statistical data. SmartChineseAnalyzer has an included dictionary out-of-box. The included dictionary data is from ICTCLAS1.0.
SmartChineseAnalyzer creates four terms (I + like + New Zealand (新西兰) + flower).
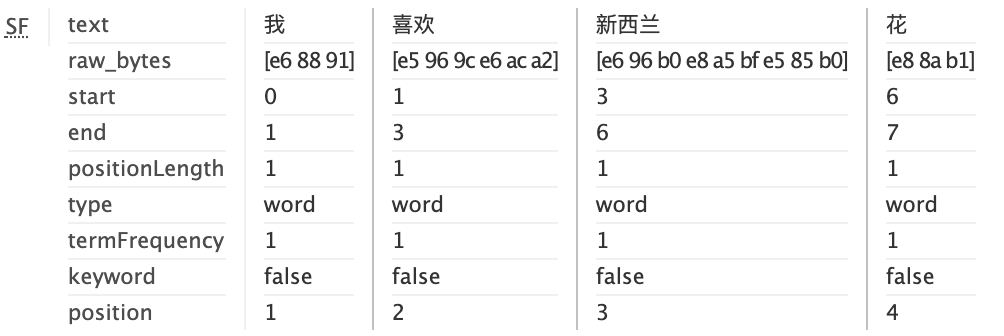
Chinese: HanLPTokenizer: Viterbi Algorithm {#HanLPTokenizer}
For our example,** HanLPTokenizer** creates six terms (I + like + New Zealand (新西兰) + Zealand(西兰) + flower):
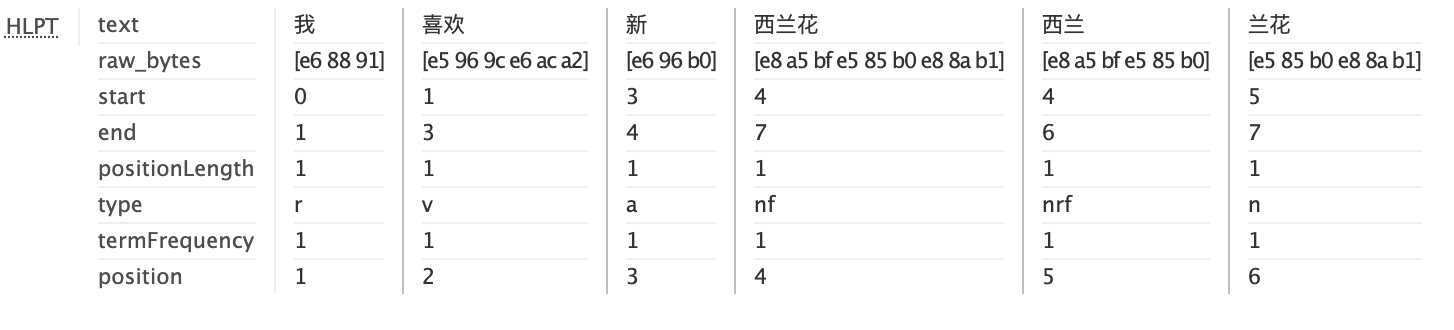
HanLPTokenizer supports the following algorithms for word segmentation:
- Viterbi (default): The best balance of efficiency and effectiveness. It is also the shortest path word segmentation, and the HanLP shortest path solution uses the Viterbi algorithm.
- Double array trie tree (dat): Extreme speed dictionary participle, tens of characters per second (may not get part of speech, depending on your dictionary)
- Conditional random field (crf): segmentation, part-of-speech tagging and named entity recognition accuracy are high, suitable for higher-demand NLP tasks
- Perceptron: word segmentation, part-of-speech tagging and named entity recognition, support for online learning
- N shortest (nshort): Named entity recognition is slightly better, sacrificing speed
Unlike SmartChineseAnalyzer, HanLPTokenizer can support Traditional Chinese as well.
Japanese: Tokenizers for Apache Solr (and SAP Commerce Cloud) {#JapaneseTokenizers}
For Japanese,
- CJKAnalyzer indexes bigrams,
- Japanese Tokenizer splits the text into word units using morphological analysis, and annotates each term with part-of-speech, base form (a.k.a. lemma), reading and pronunciation.
Japanese: CJKAnalyzer
This analyzer creates bigrams in the same way as shown above for Chinese.
Japanese: Japanese Tokenizer (Kuromoji) {#JapaneseTokenizer}
This morphological tokenizer uses a rolling Viterbi search to find the least cost segmentation (path) of the incoming characters.
This tokenizer is also known as Kuromoji Japanese Morphological Analyzer (https://www.atilika.org/)
For our test query “私は日本人です” (“I’m Japanese”), it returns four terms (“I + particle + Japanese + am)

Let’s take a look at a bit more complicated sentence: 韓国に住んでいていい人に聞いた。(I asked a good person, who lives in South Korea). It consists of the following parts:
| Element | Pronounced as | Meaning |
|---|---|---|
| 韓国 | /kankoku/ | “South Korea” |
| に | /ni/ | /grammatical particle/ |
| 住んでいて | /sundeite/ | the continuous form of the verb 住む meaning “to live”. It consists of two parts: the conjugation 住んで and a special form of the auxiliary verb いて – to be. |
| いい | /ii/ | adjective, meaning “good”. |
| 人 | /hito/ | “person” |
| に | /ni/ | /grammatical particle/ |
| 聞いた | /kiita/ | past form of the verb “to ask” |
The Japanese Tokenizer gives the following output:

So, actually, we have a bit more parts than we should have, but that is really not a bad thing. The key point is that we still have correct base forms of core words of the original phrase, so that the meaning is preserved. Those additional tokens like て and で can be removed during stop-words filter, along with the grammatical particles.
In Japanese, it’s often useful to do the additional splitting of words to make sure you get hits when searching compounds nouns. For example, if you want to search for 空港 (airport) to match 関西国際空港 (Kansai International Airport), the analyzers won’t allow this since 関西国際空港 tend to be a single token meaning this specific airport. This problems is also applicable to katakana compounds such as シニアソフトウェアエンジニア (Senior Software Engineer). For that, the tokenizer supports different modes:
- Normal – regular segmentation
- Search – use a heuristic to do additional segmentation useful for search
- Extended – similar to search mode, but also unigram unknown words (experimental)
For some applications, it might be good to use search mode for indexing and normal mode for queries to increase precision and prevent parts of compounds from being matched and highlighted.
Word Normalization {#WordNormalization}
Word normalization refers to the process that maps a word to some canonical form. For example, in English the canonical form for “are”, “is”, and “being” is “be”. This normalization being performed at both index time and query time improves the accuracy of search results.
Solr uses two approaches to normalize word variations:
- Stemming. The approach to reduce the word to its root form.
- Lemmatization. The identification of the dictionary form of a word based on its context.
Solr Filters for Chinese and Japanese {#SolrFilters}
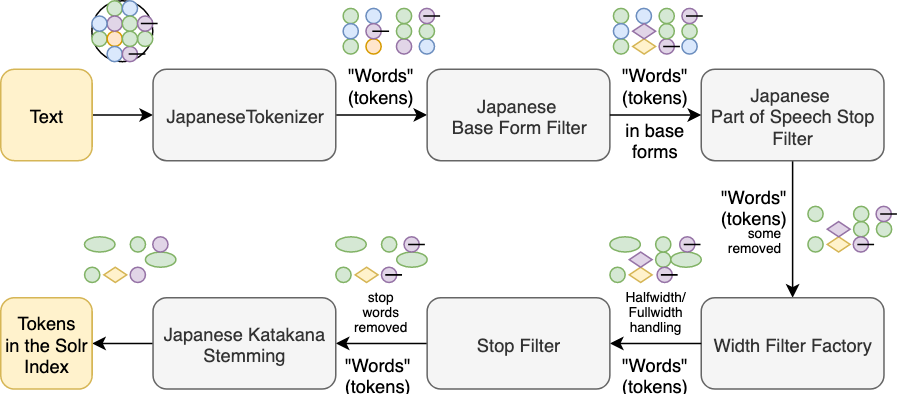
Japanese Iteration Marks {#JapaneseIterationMarks}
For stemming in Japanese, Solr provides ***JapaneseIterationMarkCharFilter ***which normalizes horizontal iteration marks (々, odoriji) to their expanded form. These marks are used to represent a duplicated character representing the same morpheme. For example, hitobito, “people”, is usually written 人々, using the kanji for 人 with an iteration mark, 々, rather than 人人, using the same kanji twice (this latter is also allowed, and in this simple case might be used because it is easier to write). By contrast, while 日々 hibi “daily, day after day” is written with the iteration mark, as the morpheme is duplicated, 日日 hinichi “number of days, date” is written with the character duplicated, because it represents different morphemes (hi and nichi).
HalfWidth Filter {#HalfWidthFilter}
By convention, 1/2 Em wide characters are called “halfwidth”; the others are called correspondingly “fullwidth” characters. CJKWidthFilterfolds fullwidth ASCII variants into the equivalent basic latin (“IjI” -> “IjI”) and halfwidth Katakana variants into the equivalent Japanese kana (カ -> カ).
Japanese Base Form Filter {#JapaneseBaseFormFilter}
JapaneseBaseFormFilter reduces inflected Japanese verbs and adjectives to their base/dictionary forms.

For example, for the phrase “それをください。” (That one, please.), the tokenizer will combine last characters together into a polite form of “ください” (“please do for me”). The BaseFormFilter converts it into the base form, “くださる”.
| Before | After |
|---|---|
| ください | くださる |
Japanese Non-meaningful Terms Removal Filter {#JapaneseNonMeaningfulTermsRemovalFilter}
JapanesePartOfSpeechStopFilterFactory removes token with certain part-of-speech tags (created by the JapaneseTokenizer). For example, “を”, the direct object particle, will be removed by this filter from the token stream.
| Before | After | Comments |
|---|---|---|
| (それ), (を), (ください) | (それ), (ください) | “を” is an auxiliary word, a Japanese particle. It is attached to the end of a word それ to signify that that word is the direct object of the verb. |
Japanese Katakana Stemming {#JapaneseKatakanaStemming}
* JapaneseKatakanaStemFilter* normalizes common katakana spelling variations ending in a long sound character (U+30FC, “ー “) by removing the long sound character. Only katakana words longer than four characters are processed.
For example, for the phrase “明後日パーティーに行く予定がある。図書館で資料をコピーしました。” (“I plan to go to a party the day after tomorrow. I copied the materials in the library.”), the word パーティー (“party”) has a long sound character in the middle and at the end. The ending symbol is removed by this filter.
| Before | After | Comments |
|---|---|---|
| パーティー | パーティ | This word is “party”. It is borrowed from English. |
| コピー | コピー | Shorter than 4 |
Apache Solr processing flow for Japanese
Apache Solr Processing Flow for Chinese
Numerals {#Numerals}
In Japan and China, most people and institutions primarily use Arabic numerals. Chinese numerals in the web forms are used too (both in China and Japan) but much less frequently. However, this does not rule out the necessity to support Chinese and Japanese specifics in using numerals.
For Chinese, it is obvious that combinations of numbers and characters can be used, but it is preferred to use the shortest written way:
| English | preferable | secondary preferable |
|---|---|---|
| one | 一 | |
| two | 二 | |
| tree | 三 | |
| one thousand | 一千 | |
| ten thousands | 一万 | |
| 1 | 1 | 一 |
| 2 | 2 | 二 |
| 3 | 3 | 三 |
| 10 | 十 | 10 |
| 100 | 100 | 一百 |
| 1000 | 一千 | 1000 |
| 1500 | 1500 | 一千五 |
| 2000 | 2千 | 两千 |
| 10000 | 一万 | |
| 100000 | 十万 | |
| 25000000 | 2500万 | 两千五百万 |
Japanese numerals are often written using a combination of kanji and Arabic numbers with various kinds of punctuation. For example, 3.2千 means 3200. Other examples are listed in the table below.
Apache Solr comes with the JapaneseNumberFilter which normalizes Japanese numbers to regular Arabic decimal numbers. This filter does this kind of normalization and allows a search for 3200 to match 3.2千 in text, but can also be used to make range facets based on the normalized numbers and so on.
The table below shows the examples of conversions supported by the JapaneseNumberFilter:
| Before | After | Comments |
|---|---|---|
| 〇〇七 | 7 | 〇 (maru) is the same as numeral 0 in English. |
| 一〇〇〇 | 1000 | |
| 三千2百2十三 | 3223 | |
| 兆六百万五千 | 1000006005001 | |
| 3.2千 | 3200 | 千 means 1000 “.” is a double-byte point |
| 1.2万345.67 | 12345.67 | |
| 4,647.100 | 4647.1 | “,” is ignored (removed) |
| 15,7 | 157 | “,” is ignored (removed) |
| 2,500万 | 25000000 | 万 means 10000 |
The last example shows one of the weaknesses of the filter you need aware of. Commas are almost arbitrary and mean nothing.
This filter may in some cases normalize tokens that are not numbers. For example, 田中京一 is a name and means Tanaka Kyōichi, but 京一 (Kyōichi) out of context can strictly speaking also represent the number 10000000000000001. This filter respects the KeywordAttribute which can be used to prevent specific normalizations from happening.
Japanese formal numbers (daiji), accounting numbers and decimal fractions are currently not supported by the filter.
Synonyms {#Synonyms}
In Japanese, as well as in many other languages, for the same concept you can find more than one word:
| Concept: to cause to die English: |
Japanese: |
|---|---|
| to kill | 殺す |
| to commit murder | 殺人を犯す |
| to murder | 殺害する |
| to shoot to death | 射殺する |
| to assassinate | 暗殺する |
| to execute | 処刑する |
Apache Solr supports synonyms, but the dictionary of the synonymous words is user-defined.
Homophones {#Homophones}
Homophones are one of two or more words that are pronounced the same but differ in writing and usually in meaning. In English, the examples are “principal” and “principle”.
Jack Halpern in “The Complexities of Japanese Homophones” illustrates this with the phrase “A Mansion with no Sunshine”. There are twelve legitimate ways (some more likely than others) of how to write this:
- 日の差さない屋敷 (standard dictionary form)
- 日の射さない屋敷
- 日のささない屋敷
- 日の射さない邸
- 日の差さない邸
- 日のささない邸
- 陽の射さない屋敷
- 陽の差さない屋敷
- 陽のささない屋敷
- 陽の射さない邸
- 陽の差さない邸
- 陽のささない邸
Halpern surveyed six native Japanese speakers, some of whom are professional translators and writers, asking them how they would write the above phrase. He reports that there were six different answers, none of which matched the “standard” form found in dictionaries.
Japanese has orthographic variants based on phonetic substitution. Jack Halpern in its “The Challenges of Intelligent Japanese Searching” mentioned the following example of that: 盲 is interchangeable with 妄 in such compounds as 妄想 (=盲想) ‘wild idea’, but not in 盲従 moojuu ‘blind obedience’.
Every written Japanese and Chinese word has at least two completely different spellings.
Such diversity naturally causes diversity in the ways how users formulate the query.
Because of a small stock of phonemes in Japanese and Chinese, the number of homophones is very large. Since many homophones are nearly synonymous or even identical in meaning, they are easily confused.
You need to have a semantically classified database of homophones to implement cross-homophone searching. The major issue is that for many homophones, a universally-accepted orthography does not exist. The choice of character should be based on meaning, but in fact it is often unpredictable and governed by the personal preferences of the writer.
For example, Jack Halpern in “The Complexities of Japanese Homophones” illustrates this problem with the following example:
| English | Standard | Sometimes | Often also |
|---|---|---|---|
| to offer | 差す | さす | |
| to hold up | 差す | さす | |
| to pour into | 差す | 注す | さす |
| to color | 差す | 注す | さす |
| to shine on | 差す | 射す | さす |
| to aim at | 指す | 差す | |
| to point to | 指す | さす | |
| to stab | 刺す | さす | |
| to leave unfinished | さす | 止す |
Since similar terms can be spelled different ways, people sometimes purposely use the wrong Kanji because it took too long to type a proper one. The local and global Internet search services (Google Japan, Baidu, Google Hong Kong, and others) can handle such cases. The users are getting used to such a response and use the same pattern at the websites. The search engines integrated into the e-stores are not so smart and the search results aren’t going to be as fruitful.
| Synonym | Synonym | |
|---|---|---|
| fox | フォックス | キツネ |
Search by pronunciation {#SearchByPronunciation}
In Japanese, the pronunciation is directly mapped to the written words. For example, Google, when searching by “とうきょうえ” (tōkyōe) correctly suggests “東京駅” (tōkyōeki) (Tokyo station). While they are written in completely different characters, their pronunciation starts with the same syllables. And the other reason is that this is how Japanese people type: they type words in hiragana and then convert them to kanji or katakana by pressing a hotkey several times until the desired conversion variant is in place.
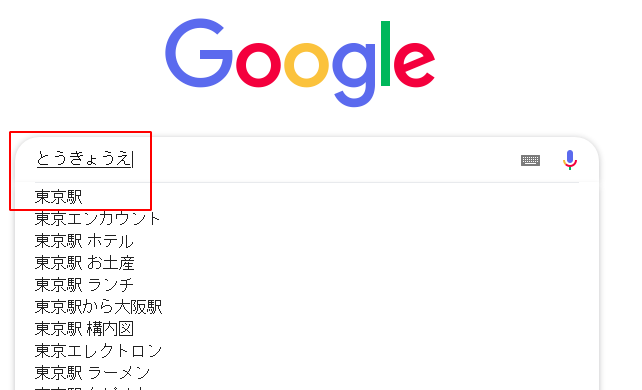
Another example, searching for 京都大学図書館 – “Kyoto University Library”

Punctuation marks {#PunctuationMarks}
There are punctuation marks specific for Japanese and Chinese. Some of them have similar-looking equivalents in European languages which are not always interchangeable.
| Punctuation marks | Example | Explanation |
|---|---|---|
| 〜 | 1〜2 | Wavy dash, for ranges |
| 。 | Full stop (=”.”) | |
| 、 | a、b、c | Enumeration comma |
| 「 」 | 「あいうえお」 | The Japanese equivalent of quotation marks (“”) in other languages. |
| ・ | ジョン・ドゥ /John Doe/ | Japanese specific: 中点(nakaten) is used to indicate a break in foreign names and phrases. Most commonly it is placed between the first name and the last name written in katakana. |
Search UI observations {#SearchUI}
Reviewed Chinese Online Stores {#ReviewedChineseStores}
- Suning.com.
- Gome.com.cn
- Taobao.com
- Tmall.com
- Jd.com
- Vip.com
- Dangdang.com
- Fanli.com
- Ly.com
- 1688.com
- Zhe800.com
- mizhe.com
Reviewed Japanese Online Stores {#ReviewedJapaneseStores}
There are some points which are differently valued by users when compared with western user interface design.
Chinese and Japanese websites have much less negative space, tiny images (and few of them), and a totally different content presentation with a focus on content rather than on its style. The density of information is higher than we got used to dealing with. Possibly , this layout style is connected to Kanban culture with its tendency to content efficiency: placing a maximum amount of content within a minimum space.
Chinese and Japanese Input Methods {#InputMethods}
Text Input in Chinese
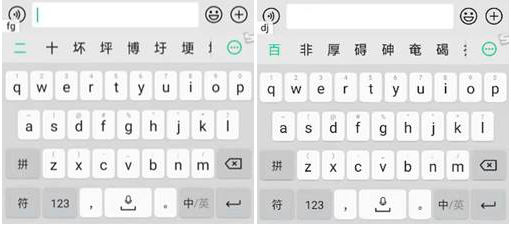
Chinese websites rely on different ways of input in Chinese characters: Pinyin (a system of Latin transcription of Chinese characters), Sequence of Strokes, Wubi (5 Basic Strokes), Handwriting, Image recognition, and voice input. The computer converts the Pinyin spelled, handwritten, captured or voiced sentence into the correct Chinese character sequence on the screen. Below is functionality offered by the default Chinese version of Android (I should say that it matches input methods in windows):

Below I tried to input 2 characters (十 – ten and 百 – hundred) by using a different method.
**Wubi (5 strokes). **Wubi is the fastest method, but the most challenging. With Wubi, all characters can be written reliably with no more than 5 keystrokes. The method requires only 2 clicks on a keyboard to spell most of the characters. But it requires to memorize a table to map strokes to keys on keyboard. Pinyin knowledge is not required, so it is widely used among Chinese who don’t know Pinyin.
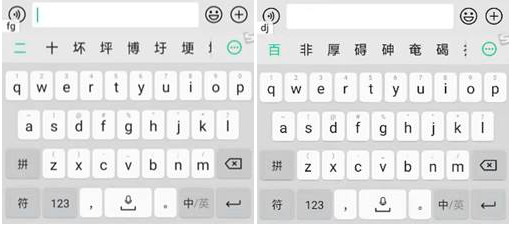
**Pinyin (with 26 English keys). **Pinyin the slowest method, I clicked 4 times before I go get each of the characters. Once a word has been typed in Pinyin, the computer will suggest words matching this pronunciation in a pop-up window. Selecting the intended word from the list can slow down the typing process considerably. But this method is commonly used among young generation who usually learn Pinyin at school. Also, the most popular method among foreigners, because it doesn’t require large vocabulary.
**Handwriting. **This method is widely used among them who don’t know Latin alphabets or by those who enjoy calligraphy.
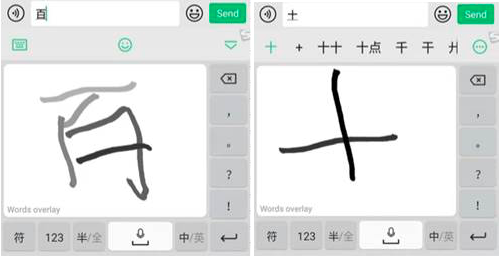
**Stroke sequence. **This method is widely used among them who don’t know Latin alphabets and not that good with handwriting. Originally method used in traditional mobile phones with small non-responsive screens. As far as strokes are grouped, the sequence might be long which slows down the process.
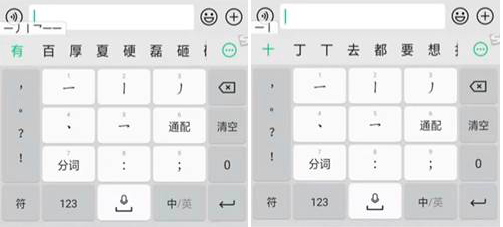
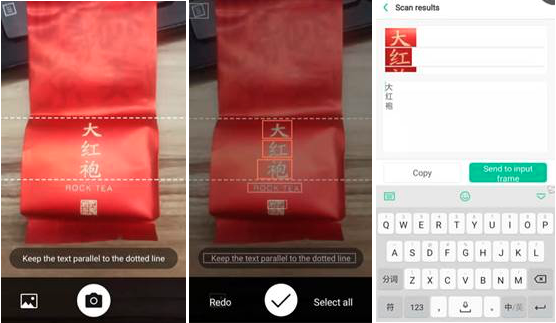
Image recognition. This method is great for the larger amount of data, doesn’t require any special knowledge.
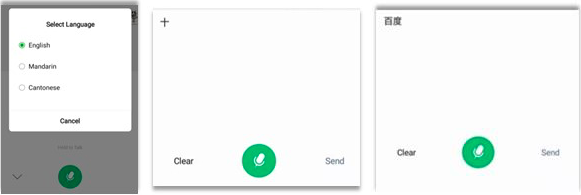
Voice recognition
Quite popular in China, but the methodology is facing a challenge because of many variant dialects causing pronunciation differences. Voice recognition projects are presumingly supported by the government as part of countrywide Putonghua popularization. Dmitry Antonov: “In my case, it used Baidu engine (AI/ML) and it smartly returned me it’s brand name Baidu when I pronounced “bai” – hundred in Pinyin, so it is commercialized advertising?”.
Text Input in Japanese
There are two main methods of inputting Japanese: Romaji, via a romanized version of Japanese, and Kana. The keyboards sold in Japan usually look like this:

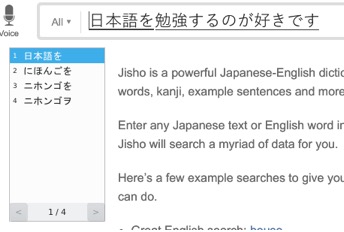
The primary input method is typing words by their reading in kana and then convert them to kanji. For example, let’s see how to type phrase 日本語を勉強するのが好きです — “I like studying Japanese”.
You type your sentence in hiragana first, at this step it looks like this:

Then you press the conversion key and it converts the current word to the kanji or katakana representation. Because there are many homonyms, often you will see the little window pop up with a list of conversion variants. It looks like this:
Then you convert each part until you get the needed result.
On a typical Japanese keyboard there are five helper keys:
- 変換 — /henkan/, meaning “conversion”. Converts kana to kanji.
- 無変換 — /muhenkan/, “no conversion”. Leaves the kana as it is.
- かな, or simply “kana” — kana mode. Also there may be keys for specific kana modes: ひらがな(hiragana), カタカナ(katakana) or ローマ字(romaji).
- 英数 — /eisu/, alphanumeric mode.
- 半角/全角 — /hankaku, zenkaku/, half-width and full-width mode for inputting latin characters.
If one doesn’t have a keyboard with kana support, they can type in romaji. The process is exactly the same, except the first step: instead of typing hiragana directly, you type kana readings in romaji and they are automatically converted into hiragana:
Less search, more navigation
It is common to find the search field a lot less highlighted on the Japanese and Chinese websites. According to Alex Zito-Wolf, “Chinese UI Trends”, Chinese apps and websites tend to prioritize navigation over search. With the Japanese keyboard, it takes about 20+ keypresses to type a few Japanese characters, so it is often faster to get to a particular link than typing something in search.
Zito-Wolf also highlights that many apps use a focus page which is activated once the user clicks on the search bar. The author believes that “Chinese apps create strong hooks to allow users to be routed away from using text search at the beginning of the search process, allowing these users a faster search completion and more time spent browsing other pages.” This focus page contains the tags which are meant to help the user find the fastest way to construct a search, as well as educate them on how to effectively write search queries improving search efficiency in the long run.
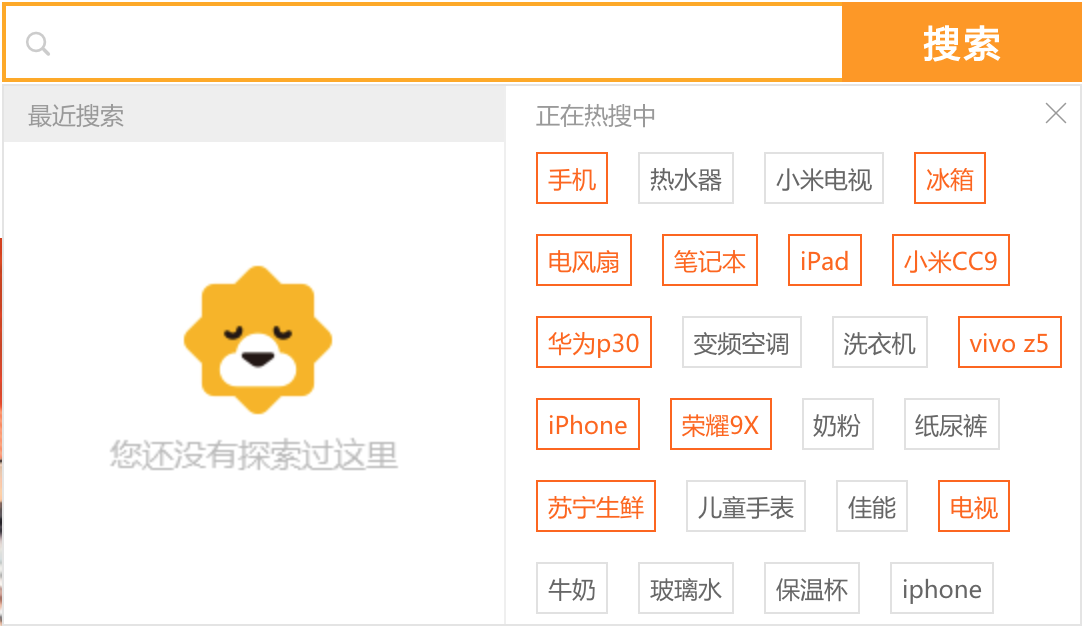
(Suning.com)
The mobile version of Suning.com redirects the user to a designated search page (/search.html) when a user clicks on the search bar.
Zito-Wolf draws attention to the high role of tags in the search process. “For the query 咖啡 (“Coffee”) (…) like a guessing tree, the system starts with broad additional tags, 价格比高 “Good cost/value ratio”, 交通方便 “Convenient transportation” and 就餐空间大 “Spacious atmosphere”.
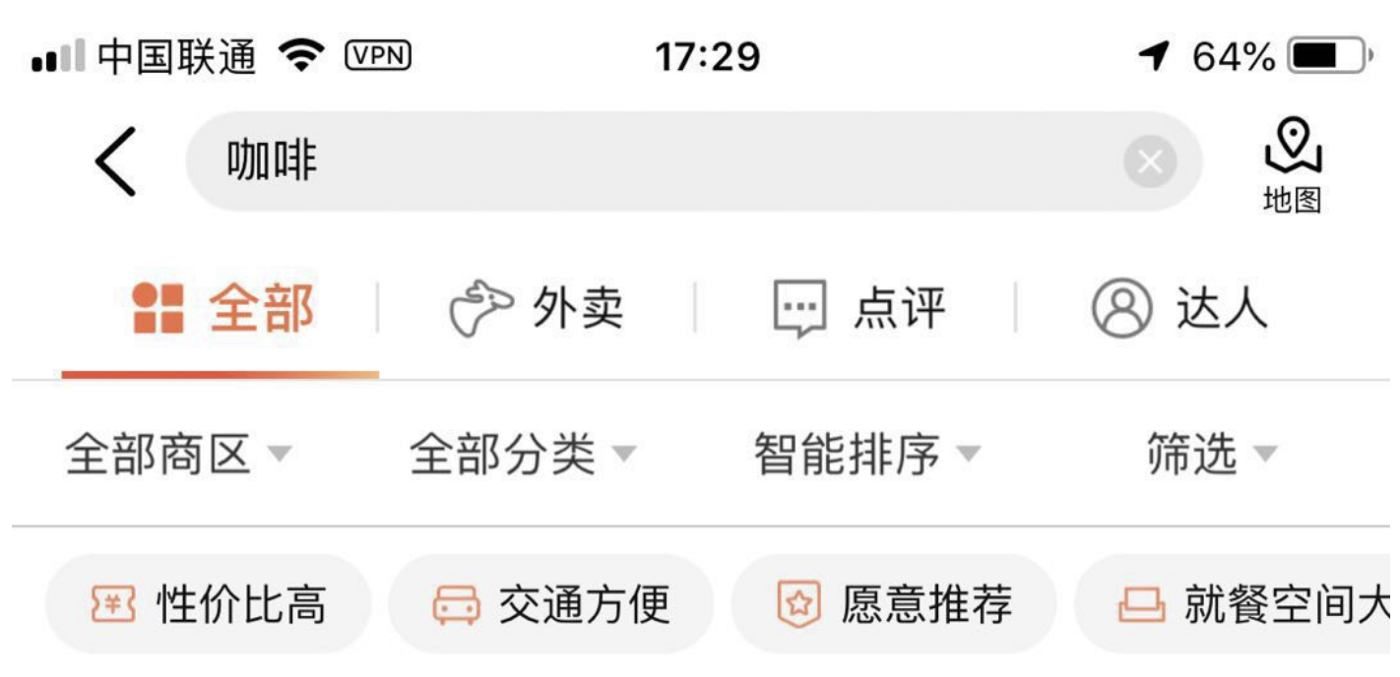
Voice search
The UX/UI Designer Pavlo Plakhotia notices that the implementation of the voice message function is very common for Chinese mobile design. “Voice control is much easier than manual text input, especially for the older audience, who do not always have sufficient skills to work with mobile applications and various ways of entering the set of Chinese hieroglyphs. At present, there is also a trend among users to exploit voice input for search queries instead of typing.”
Gome.com.cn:

Context-aware query recommendations {#ContextAwareQueryRecommendations}
Many websites show the context/recommended queries under the search bar. This list depends on context and customer behavior. For example, after searching “iphone”, the system understands that the user wants a mobile phone, and recommends other brands too (Huawei, Samsung, Oppo, Vivo)
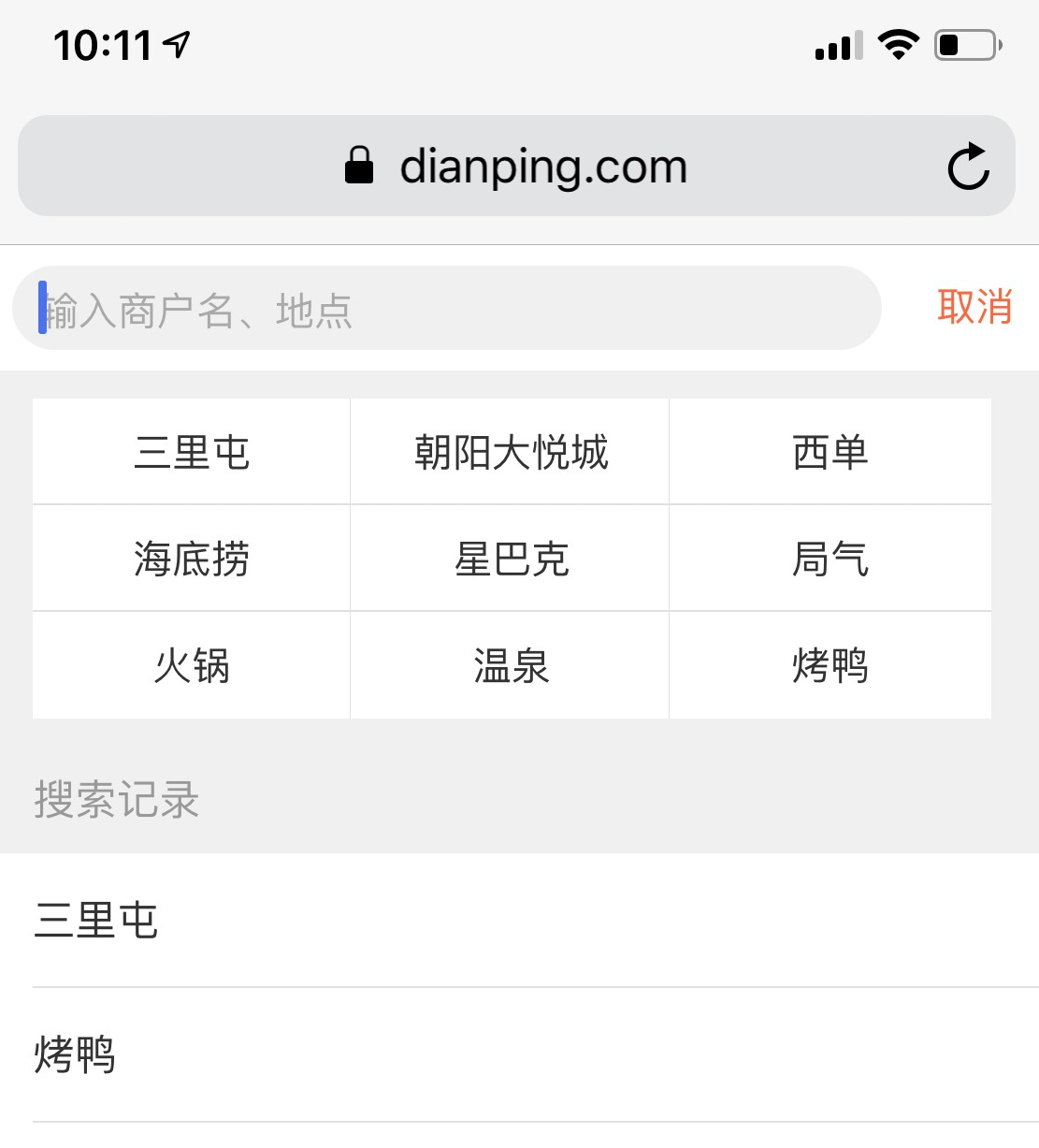
Tmail.com:

Dianping.com:

The recommendations can be even placed inside the search box (this is travel e-shop, and recommendations are destinations, Suzhou and Shanghai)

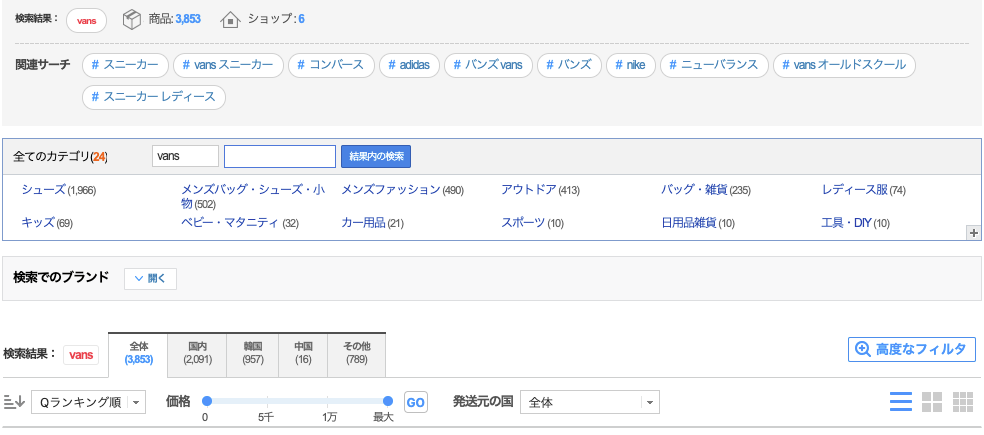
In Japanese stores there are also related queries (qoo10.jp, the query is “vans”):

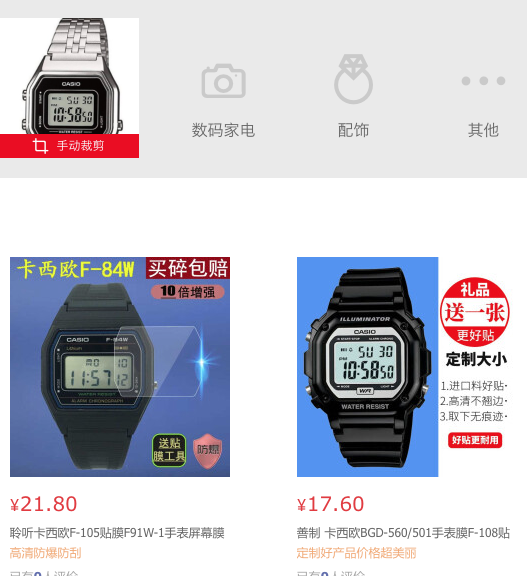
Visual search {#VisualSearch}
The trend in more and more shops implement visual search.
1688.com:

JD.com:

The image I used for search:

The results:
No alpha sorting
In Chinese, there is no meaning to sort the search items or facets by alphabet because there is no alphabet. Theoretically, the items can be sorted by the character’s rendering into Pinyin based on Pinyin alphabetical order in the manner as many dictionaries do.
In other aspects, the search box and search results page follow the general market-agnostic UI/UX recommendations.
Facet panel {#FacetPanel}
Facets are often arranged horizontally because of the Chinese and Japanese script is much denser. However, that is more a characteristic of Chinese websites:
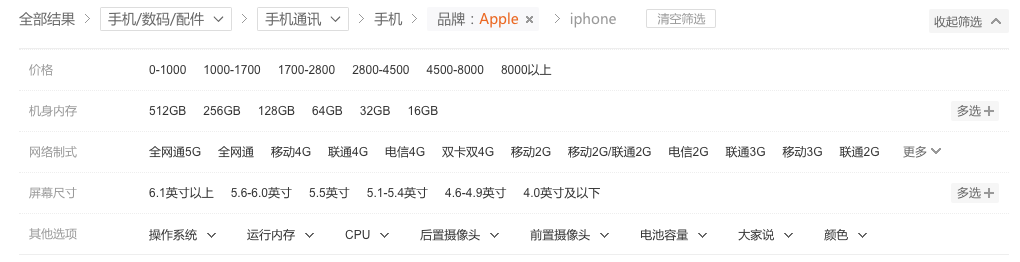
Zhe800.com:

JD.com:
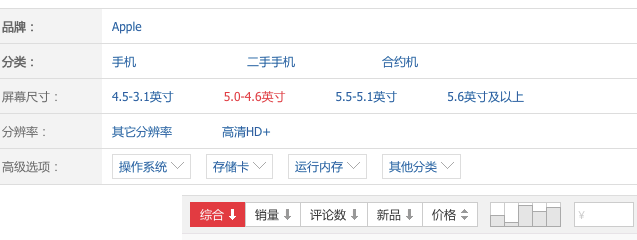
Gone.com.cn:
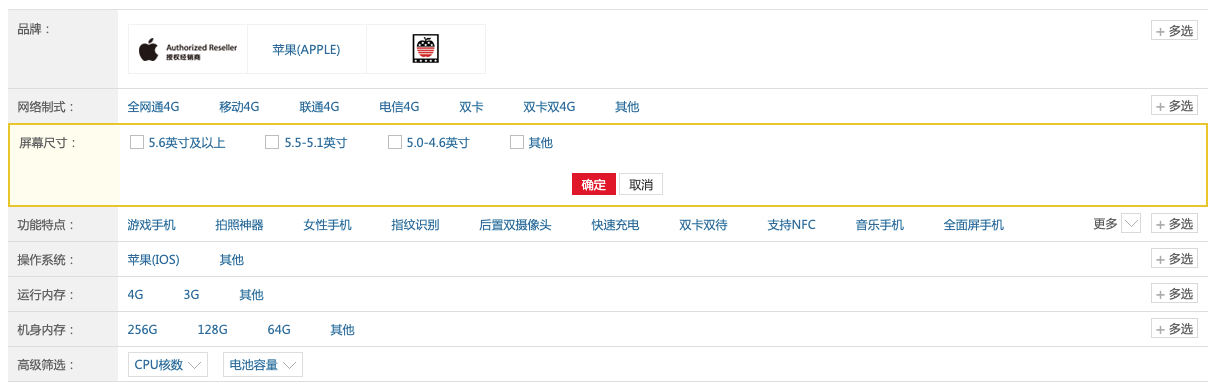
All important facets are open by default, all others are collapsed. You can expand them on hover. In the next screenshot, the facet with the list of tags is opened:

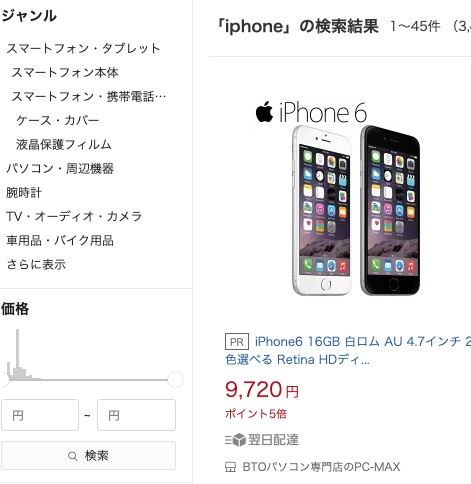
In Japan, vertical facets are more common:
Rakuten.co.jp:
Zozo.jp:
Wowma.jp:
Horizontal facets are used too on Japan’s websites, but it is not so common.
Recommendations {#Recommendations}
If your website is available in different language versions, you need to have answers to the following questions:
- What languages can be used on what language versions? Can I search in Chinese on the English website and vice versa?
- Can we mix English and Chinese in the same query? It is especially important for brands and proper names (Sony / ソニー).
- What language variants are supported?
Web typography recommendations {#WebTypography}
The best line length is 15-40 characters per line (CPL) for the computer display and 15-21 CPL for the smartphone display (~2 times shorter than it is recommended for English)
In Japanese, Serif (with decorative elements) is called “Mincho” (明朝) and Sans-Serif (plain) is called “Gothic” (ゴシック).
In Chinese, the two most commonly used classifications are Song (宋體, 宋体) or Ming (明體 / 明体), which you could think of as the Chinese serif, and hei (黑體 / 黑体), similar to a sans-serif.
In English, the 3rd party font files have a very small impact to the page loading speed because the character set is relatively small. And the designers embed them into the pages. In Chinese and Japanese, extra fonts can be one of the reasons for a slow-loading page.
Italics is technically supported, but it not recommended to use it with Japanese and Chinese characters. It skews them so that they become unreadable.
Don’t use a font size smaller than 12pt. It’s always better to set your font size by “em” or “%” and take the user preferences into account. If your website targets older people, consider 16pt font size.
Meiryo, MS Gothic, MS Mincho, Yu Gothic, and Yu Mincho fonts are pre-installed in Windows. “Hiragino Kaku Gothic ProN” and “Hiragino Mincho ProN” are pre-installed in MacOS. “HiraKakuProN-W3” and “HiraMinProN-W3” are used in iOS.
If you want to get typography better, Noto will be a good solution. Noto is a Google font family that supports all languages including Chinese and Japanese.
Conclusions
In the above, we’ve touched different aspects of Japanese and Chinese searching. We demonstrated that the challenges are addressable. We also demonstrated that the solutions are still evolving and there are always matters outstanding for deeper research.
Because of the complexities and irregularities of the Chinese and Japanese writing systems, you need not only computational linguistic tools such as morphological analyzers, but also lexical databases fine-tuned to the needs of particular project goals and content. Both analyzers and databases are constantly improving, and it is important to keep an eye on the latest breakthroughs in information retrieval and apply them to your solution to keep delivering better user experience and better service.
As you can see, Chinese and Japanese query processing and information retrieval is not straightforward, but this topic is not new, and basic solutions are generally well-known and well-tested. This article should help with better understanding of how they work and what problems are addressed.