Introduction
The traditional Hybris Solr cluster has a number of drawbacks, including a lack of failover and scaling capabilities. In this post, I explore SolrCloud as one of the possible options for resolving these issues.
To illustrate, the traditional Hybris Solr cluster looks like this:
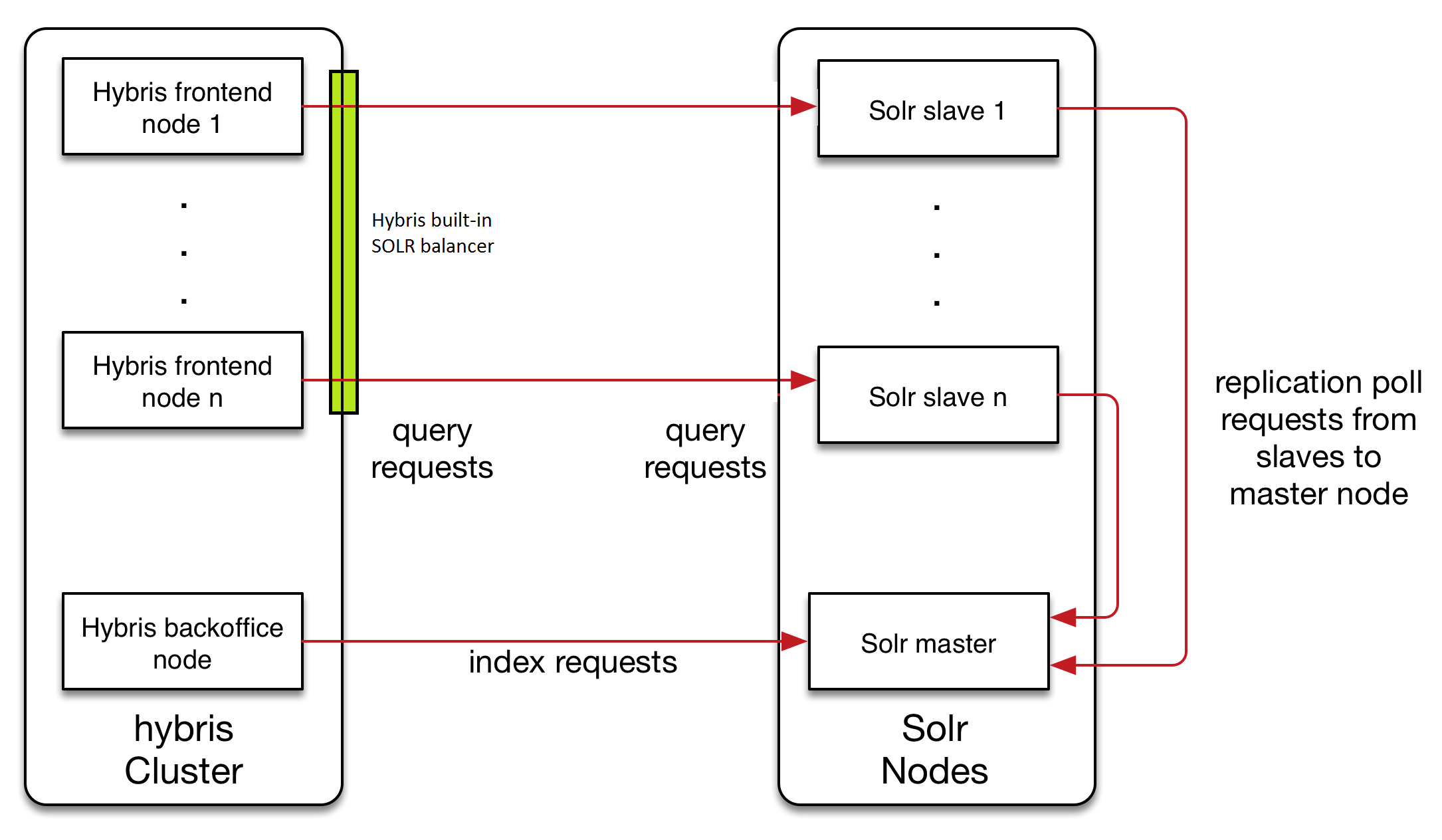
This traditional architecture has a number of drawbacks as outlined above, including:
- A lack of failover capability
- Having the cluster configuration stored in the Hybris database (non-ideal in terms of supportability)
- An inability set up autoscaling if the need arises
To mitigate these issues, there are a couple different routes you can take.
Option 1:
Implementing a load balancer to manage search requests:
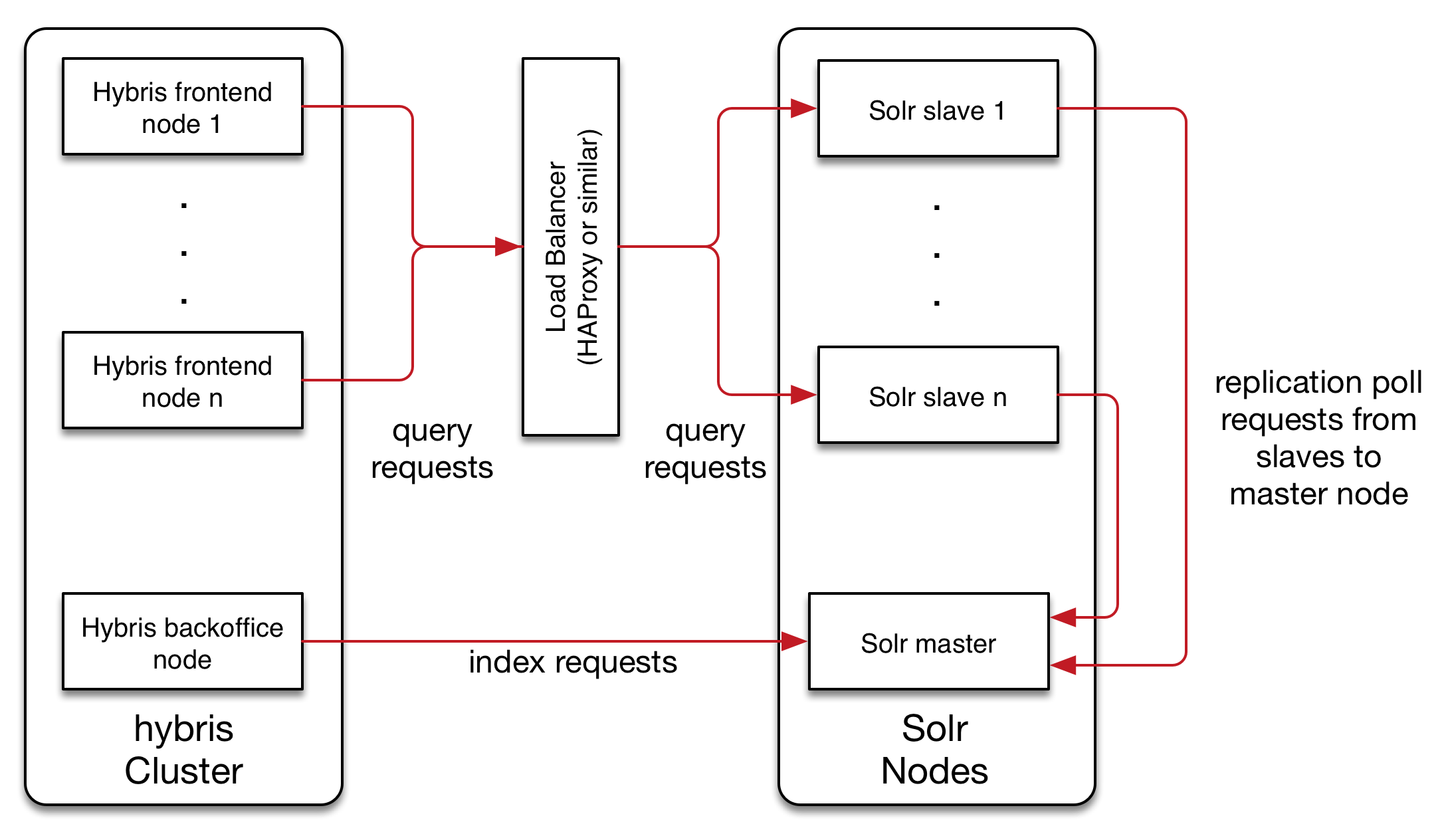
The drawback to this option is that the indexer is still not scalable, which was one of the main issues with the traditional architecture.
Option 2:
The second option, (which I’ll be focusing on for the remainder of this posting), is integrating Hybris with SolrCloud. This option resolves the scalability issue, as well provides a better failover option and gets the cluster configuration out of the Hybris database.
The target architecture should look like this:
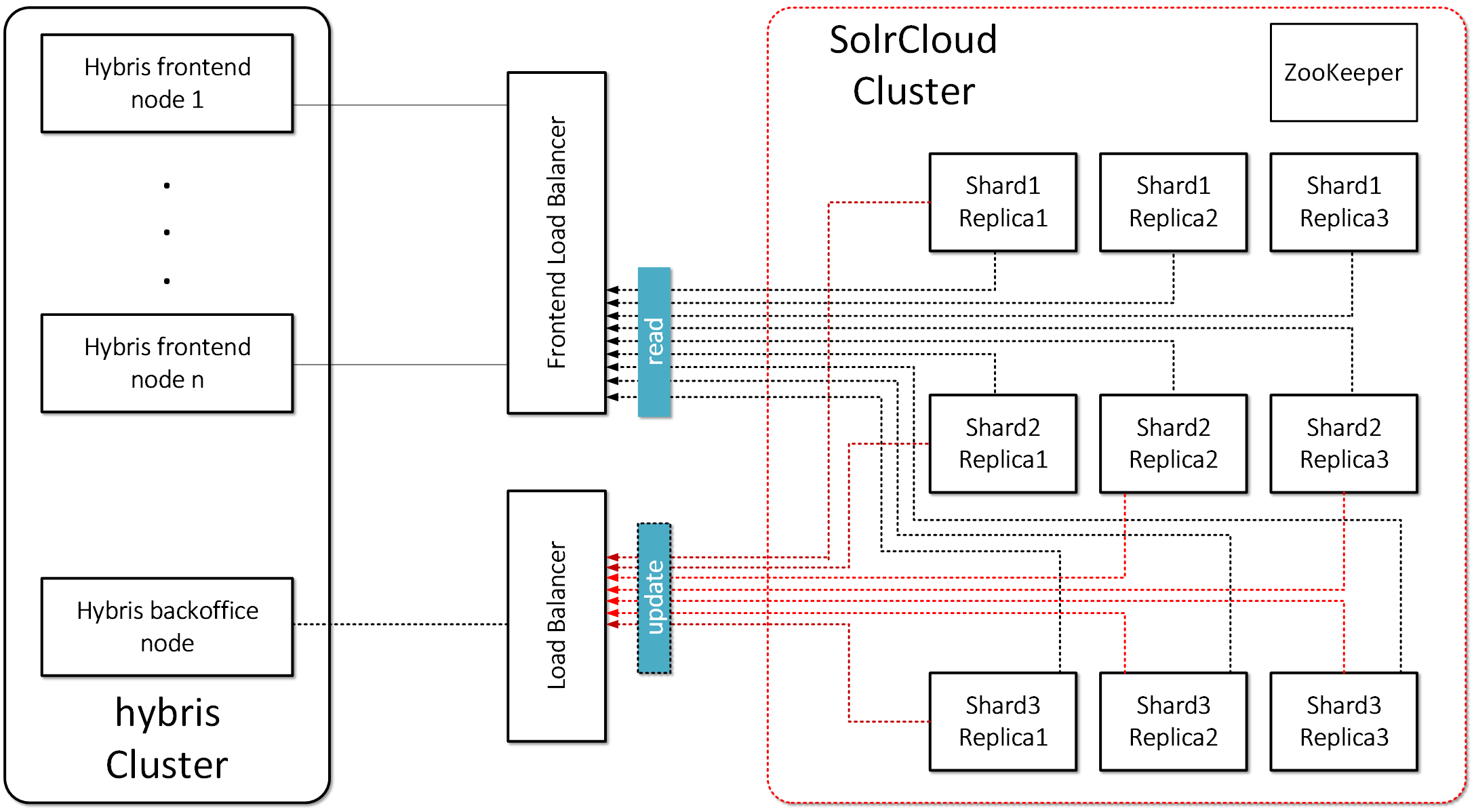
To fully understand the Solr Cloud solution, it’s necessary to first define the terminology that is used.
- Collection: Search index distributed across multiple nodes; each collection has a name, shard count, and replication factor. In my example, shard count = 3 and replication factors = 3. Collection is “master_electronics_CloudIndex_collection” and “master_apparel-uk_CloudIndex_collection”. A collection is a set of shards.
- Shard: Logical slice of a collection; a shard is a set of cores. Each shard has a name, hash range, leader, and replication factor. Documents are assigned to one (and only one) shard per collection using a document routing strategy.
- The document routing strategy is based on the hash value of the ID field by default.
- Replication Factor: The number of copies of a document in a collection. For example, a replication factor of 3 for a collection with 100M documents would equal 300M documents total across all replicas.
- Replica: A Solr index that hosts a copy of a shard in a collection. Behind the scenes, each replica is implemented as a Solr core. For example, a collection with 20 shards and replication factor of 2 in a 10 node cluster will result in 4 Solr cores per node.
- Leader: A replica in a shard that assumes special duties needed to support distributed indexing in Solr. Each shard has one (and only one) leader at any time, and leaders are elected automatically using ZooKeeper. In general, it doesn’t matter which replica is elected as the leader.
- Overseer. The overseer is the main node for a whole cluster which is responsible for processing actions involving the entire cluster.If the overseer goes down, a new node will be elected to take its place.
I’ve created a diagram below that shows how you can write to any node in the cluster and it will redirect the query to the “Leader” node. Then, the leader node will redirect the query to storage. Ultimately, the client shouldn’t be aware of leaders and shards, they simply add new data to the cloud.
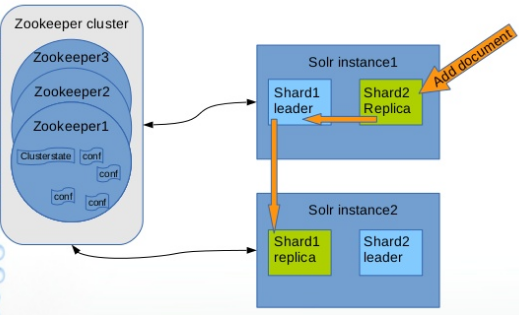
The main benefits of using SolrCloud as storage for Hybris include:
- Distributed indexing. In the traditional architecture, Hybris can only work with one indexer, which ends up becoming a bottleneck.
- Automatic fail–over. In the traditional architecture, the indexer is a weak point in terms of durability.
- Sharding. Horizontal scaling for indexing parallelization. For example, if you have 1,000,000 products and ten shard servers, each server will manage ~1/10 of 1 mln. You will be able to scale the system by adding shard servers.
- Replication. For failover correction (high availability) and load balancing. Unlike traditional SOLR replication, SolrCloud replication is not master-slave.
- Leader election. If the leader goes down, a new node will be elected to take its place. As a result, we have no SPOF.
- Overseer election. If the overseer goes down, a new node will be elected to take its place. As a result, we have no SPOF.
- Centralized configuration (Zookeeper). This feature can also be added to traditional architecture.
Complexity
Out-of-the-box Hybris doesn’t support SolrCloud. Hybris knows nothing about the SolrCloud collections; it works with cores. In the SolrCloud model, it will need to work with the collections instead.
Solution
Technical details
In summary, there are two possible solutions to improve failover capability, supportability and autoscaling over the traditional Hybris Solr cluster:
- to replace Hybris built-in indexing strategy
- to put an adapter between Hybris and SolrCloud.
I chose the second option as it overcomes more of the limitations of the traditional structure. Some of my notes:
- In my architecture, there is a load balancer (nginx) that plays the role of an adaptor and transforms incoming hybris-generated requests into the SolrCloud format. For simplicity, my load balancer works with only one host in the cloud.
- basically, it replaces “master_electronics_CloudIndex” with “master_electronics_CloudIndex_collection_shard1_replica1”. It is a straightforward way to make it work and for a real project we will need to reconsider it. However, it doesn’t mean that the node with shard1_replica1 will be loaded the most. It is a cloud, and the request may be redirected to another node based on Hash(id) + see ‘Leader’ above.
- The Hybris configuration was moved to Zookeeper. Solr uses Zookeeper as a system of record for the cluster state, for central config, and for leader election.
- The Hybris Solr plugin was moved to Solr instances in the cloud.
- There is a fake core named “master_electronics_CloudIndex”. Hybris checks the cores using checkCore() and fails with SolrCloud. Unfortunately, this functionality is critical in Hybris and difficult to turn off. It is much easier to create an empty core with the name Hybris expects and these checks will be passed.
- “CloudIndex” in the core/collection name is from itemType.indexName. By default it is empty, and Hybris uses “Product” for empty indexName (e.g. the core/collection would be named “master_electronics_Product” if indexName is empty)
- the TWO PHASE indexing mode is not working yet. I was using “DIRECT” mode. So it is in TO DO.
© Rauf Aliev, July 2016

Alexandre SIMON
29 August 2016 at 12:13
Hello,
I (we) like your website. It is rare to find any public Hybris resource 😉
So to share a little too our experience : we integrated SolrCloud with our (first) Hybris (6.0.0.0) project overriding standaloneSolrService.
The implementation is TWO PHASE compatible and did not took too much time to implement (~300 lines of code) :
* When SolrCloud is started for the first time (in fact when a Solr docker container starts), we create (if needed) some “collection workers” : ie. collections that are NOT named “master_electronics_CloudIndex” or “master_electronics_CloudIndex_1”. Let’s say we create two collections : “collection1”, “collection2”
* We then use the ALIAS command of the Collection API (https://cwiki.apache.org/confluence/display/solr/Collections+API#CollectionsAPI-api4) to attribute the name Hybris uses to the “collection workers” ; we also implemented the aliasing Hybris side when it checks for the “core” (now a collection) existence so if we missed some operation on system side, Hybris corrects it. At the end, let’s say “collection1” is aliased “master_electronics_CloudIndex” and “collection2” is aliased “master_electronics_CloudIndex_1”. Hybris will then use the collections transparently, connecting directly to Solr (via HaProxy auto-reconfigured to provide high availability).
* We had to override some methods of standaloneSolrService :
** Core checking : just checking the collection existence ; aliasing the collections if needed
** Core swapping : to implements the core swapping, we just move the aliases. The operation is not totally atomic as the swap operation was (two operations indeed : attribute “master_electronics_CloudIndex” alias and attribute “master_electronics_CloudIndex_1” alias, to the right collections and in the right order) but we accept this risk…
** Core reloading : just reloading the collection
** Core registration : aliasing the collections
Regards,
Alexandre SIMON
http://www.netapsys.fr
Rauf Aliev
29 August 2016 at 12:31
Thank you, Alexandre, for the details! Very interesting!
Rac1
1 March 2017 at 19:25
Thanks for the wonderful blog Rauf. Please can you shed some light on below topic.
We have situation where I need to write some service which will get the list of cores from Solr and then send a request to Hybris Admin backoffie node to Initiate or reindex the listed cores …I get upto the point where I able to read all core names but I am not sure how to pass these cores to Hybris admin node again to recreate or reindex , any help highly appreciated.
Thanks
Joe
Rauf Aliev
1 March 2017 at 20:07
Joe, I’m in the business trip now, the task looks vague… and I’m not sure I can help you now.. may be bit later on skype
Rac1
2 March 2017 at 14:00
HI Rauf,
I appreciate your quick turn around, i deep down a bit in to this issue and got bit more clarity, as long as some how I notify Hybris via service call and that would be good. For example , the service call has information about solr salve with CREATE option , same for Master with reindex option , so that point of time , Hybris already know how reindex or recreate , the only part I am thinking right now is what is the command i should put as part of my service call to tell Hybris so and so slave and master to be started…. does this make sense?
Thanks
Joe
Rauf Aliev
7 March 2017 at 16:45
I’m very sorry,
Now I’m very overwhelmed and can’t help you now…
Kaustav Srivastav
30 July 2017 at 11:41
How to create Solr Indexer Cron Job for two different countries ? i have two different indexedtype for the corresponding country ?
Rauf Aliev
30 July 2017 at 13:00
It’s a common thing. Two records in solr indexed cronjob, one per type
Sajid
17 November 2017 at 16:56
Great article Rauf !!
I have a question for you – Do you think Partial update is an option worth trying even after having Distributed indexing in place?
Just trying to understand if distributed indexing will eliminate the need for partial update.
Cheers
Saj
Rauf Aliev
18 November 2017 at 03:09
No, I used it with the standard configuration, but partial update is always much faster (despite the fact that internally in sole the entire document is updated)