
Situation
I am still working on overcoming hybris’ limitations. Today’s topic is personalized catalogs. In one of my previous blog posts, I talked about personalized prices for 500,000 customer groups. This time, I want to tell you about personalized product availability.
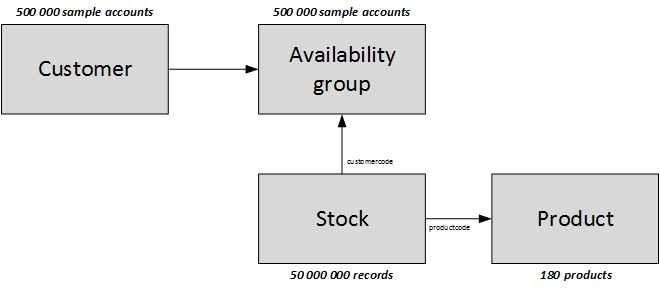
It is clear that in most cases, the number of availability groups is not very high. However, I used an extreme case: 500,000 availability groups for one e-shop, with one unique customer per group. Once this issue is solved, the approach can easily be scaled down, while recognizing possible bottlenecks and limitations.
In my example below:
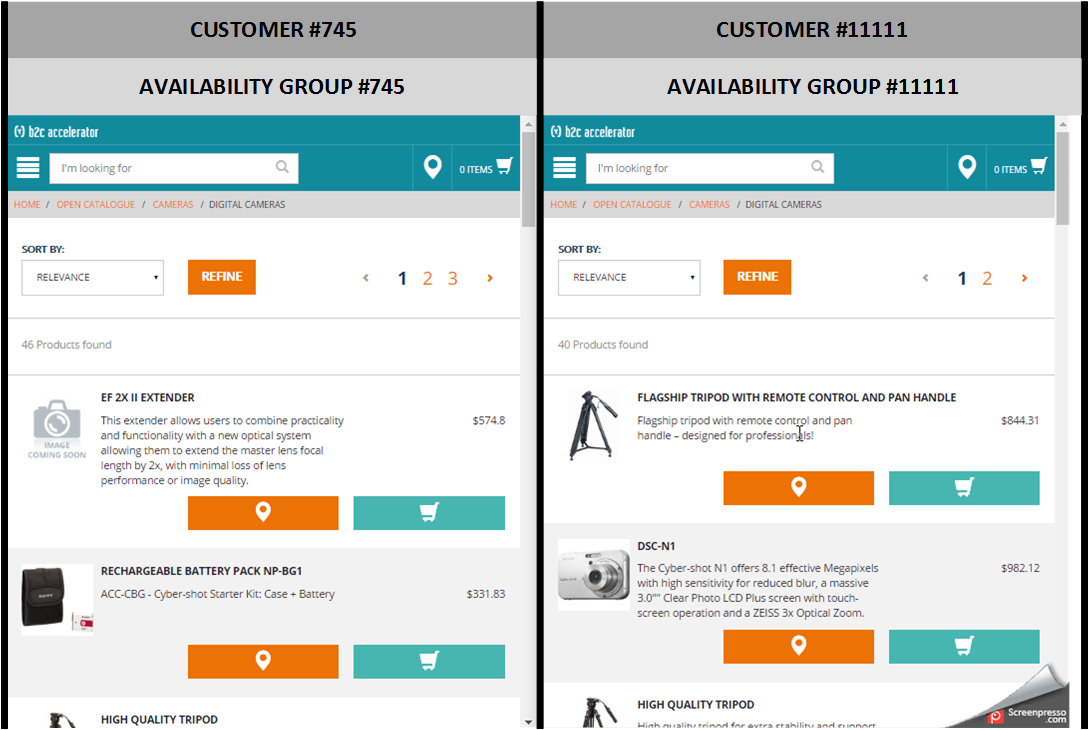
leftcustomer (#745) belongs to availability group #745.rightcustomer (#11111) belongs to availability group #11111.
| Availability group #745 | Availability group #11111 | |
|---|---|---|
| EF 2X II EXTERNDER | AVAILABLE | NOT AVAILABLE |
| RECHARGEABLE BATTERY PACK | AVAILABLE | NOT AVAILABLE |
| FLAGSHIP TRIPOD | NOT AVAILABLE | AVAILABLE |
| HIGH QUALITY TRIPOD | AVAILABLE | AVAILABLE |
The following behavior is expected (see the screenshot below). The left side is a screenshot from the device where customer #745 is logged in; the right side is for customer #11111.
Data and models
Complexity
In hybris, availability information is stored in the database and SOLR index. For category pages and search results, hybris uses SOLR. For product pages, it uses information from the database. Indexing is a slow process for large, comprehensive catalogs, so it is common for the information in these sources to be different. However, product information such as product attributes, title, description, or product images does not change frequently, while product data such as prices and stock data is very dynamic.
However, the indexing logic is arranged in hybris so that almost all information is retrieved from the database for indexing purposes. If your stock is very dynamic, you need to launch a new indexing process just after the previous one is complete. Sometimes indexing can take hours. This can mean that information about product availability will not be relevant for a large number of products for a significant amount of time.
One solution is to change the availability information directly, without touching the other fields. It is a good approach, but I’m not satisfied with the performance.
Solution
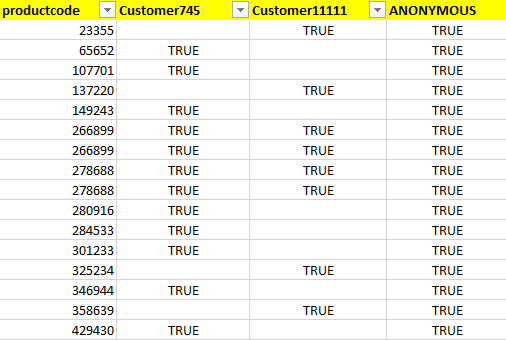
- There is a separate SOLR core to handle availability groups. The configuration of this core is rather basic. This is a simple four-column dataset:
customercode,productid,AvailableOrNot.
customercode,productcode,stock
customer1,107701,true
customer1,479956,true
customer1,592506,true
customer1,824259,true- It is very fast to update with information from the warehouse management system or ERP system. A full update (50M records) takes 187 seconds.
- The database is used only to handle availability groups. Stock information is stored in SOLR. Hybris stock data is not used anymore. For compatibility, you might sync SOLR data with hybris data when needed, and only for the affected items.
Technical details
SOLR
New core: personalstock. Configuration:
Uploading data:
time -p curl "http://localhost:8983/solr/personalstock/update/csv?stream.file=/hybris/solr-prices/stock.csv&stream.contentType=text/plain;charset=utf-8"See above for the Stock.csv structure.
Custom SOLRQueryConvertor
To use this additional core, you need to slightly change the requests for SOLR from hybris. There is a query parser plugin named JOIN that can be leveraged to use the data from our new SOLR core.
public class DSSOLRQueryConvertor extends DefaultSolrQueryConverter implements SolrQueryConverter, BeanFactoryAware {
@Resource
UserService userService;
public SolrQuery convertSolrQuery(SearchQuery searchQuery) throws FacetSearchException {
SolrQuery solrQuery = super.convertSolrQuery(searchQuery);
String customerAvailabilityGroup = getAvailabilityGroupOftheCurrentCustomer();;
String customerQuery="*:*";
if (!customerAvailabilityGroup.equals("")) {
customerQuery = "customercode:" + customerAvailabilityGroup;
solrQuery.add("fq", "{!join from=productcode to=code_string fromIndex=personalstock}"+customerQuery);
}
return solrQuery;
}
private String getAvailabilityGroupOftheCurrentCustomer() {
AvailabilityGroupModel AvailabilityGroupModel = userService.getCurrentUser().getAvailabilityGroup();
currentAvailabilityGroup = AvailabilityGroupModel.getCode();
return currentAvailabilityGroup;
}
}© Rauf Aliev, June 2016