
This article focuses on how SAP Commerce stores models in memory, which is a vast topic. To begin with, we will explore a relatively simple aspect: the unusual structure that appears in the debugger when trying to view the contents of any SAP Commerce model. We will also discuss how to access all the object properties contained within it.
The model classes in SAP Commerce are organized into a hierarchy with AbstractItemModel as the root class. The model classes extending ItemModel are generated, so their interface matches the XML definition. If you add a new attribute, a getter and setter will be automatically added to the model class.
In the diagram below, CMSSiteModel and BaseSiteModel are generated. The models are normally compiled and packaged in model.jar.
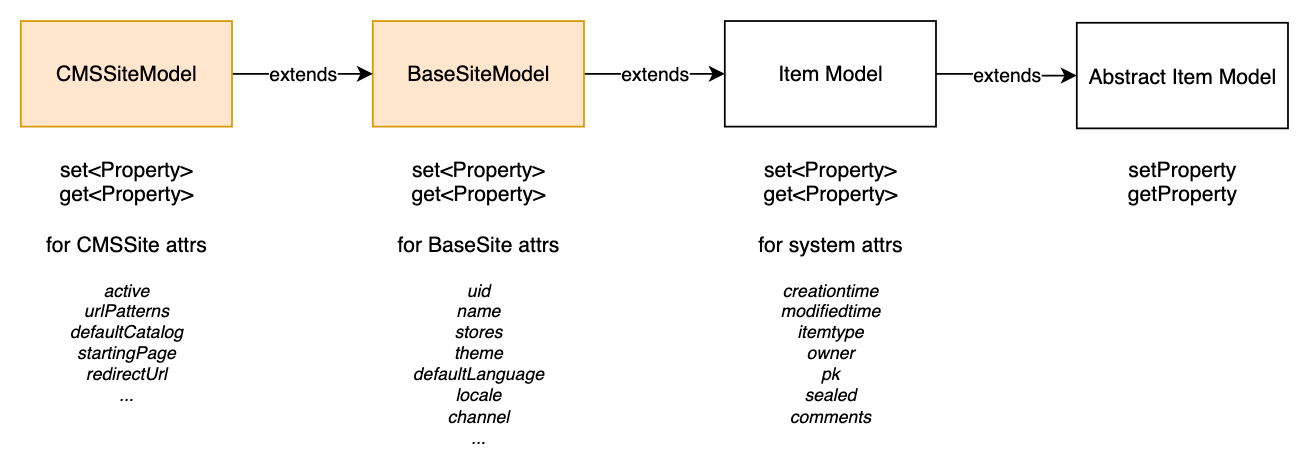
Each model class has a set of static constant fields, getters, and setters acting as adapters to the getProperty and setProperty methods of AbstractItemModel. This means that the attributes defined in the items.xml file do not have corresponding class attributes with the same names. Instead, they have corresponding getters and setters.
Let’s look at how a model instance is represented in the debug panel in IntelliJ IDEA. There is absolutely nothing familiar or expected here.
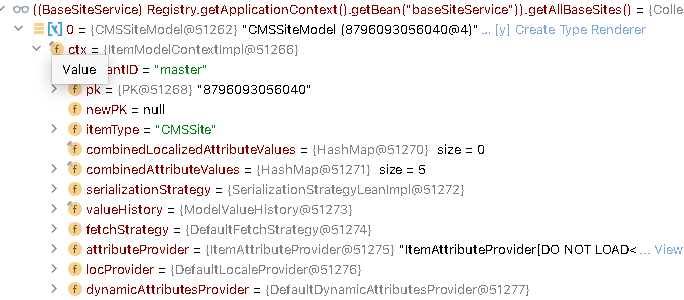
What you see in the debugger window is what ItemModelInternalContext contains for a model class. The ctx attribute is private, so you can’t access it via the code, but IntelliJ IDEA can pull it into the debug panel. However, IntelliJ IDEA and other IDEs can’t use getters for a class unless you install a plugin for SAP Commerce; they can show class variables.
Okay, let’s look at what IntelliJ IDEA shows when SAP Commerce model class instance details are requested.
The first obvious question a junior developer may ask is: where are the model attributes? After expanding the properties, one can quickly find some attributes, such as uid or name. Just to jump ahead, I’ll say that they are in combinedAttributeValues and valueHistory.originalValues, and in their localized counterparts.

But one will notice very quickly that not all attributes are there. The question is: where are the rest of them?
The more challenging question is how to see all attributes with all values for an object instance in the debugger window. Where is the rest?
It’s arranged quite cunningly.
Studying how ItemModelContextImpl works helps to understand the internals of the SAP Commerce persistence system.
combinedAttributeValues
Think of combinedAttributeValues as caches for a subset of the attributes of the model. They are updated when you do setProperty(value). An item is marked as dirty in this case; see valueHistory below for details. They are used as a cache when you do getProperty(attrname). If the cache is not populated, the system pulls data from the database via ItemModelContextImpl.getValue, which uses an AttributeProvider.getAttribute.
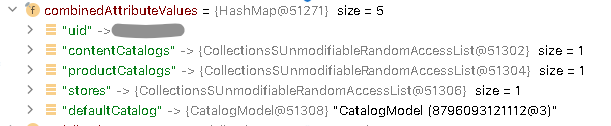
combinedLocalizedAttributeValues
The combinedLocalizedAttributeValues property is similar to combinedAttributeValues, but it is used for localized attributes.
But I Have More Attributes for CMS Site Model! Where Are They?
It’s worth noting that a cache doesn’t necessarily need to hold all items within it. Only the ones requested recently are there.
If you really want to see all the attributes, consider using a plugin for IDEA to render such models via getters. Download it here: https://plugins.jetbrains.com/plugin/12867-sap-commerce-developers-toolset. This plugin is being developed by EPAM Systems. There are a few detailed articles on Hybrismart.com on this topic.
But yes, not all attributes are listed in combinedAttributeValues and combinedLocalizedAttributeValues.
In my example, some additional attributes, such as channel and solrFacetSearchConfiguration, are listed in valueHistory.originalValues:
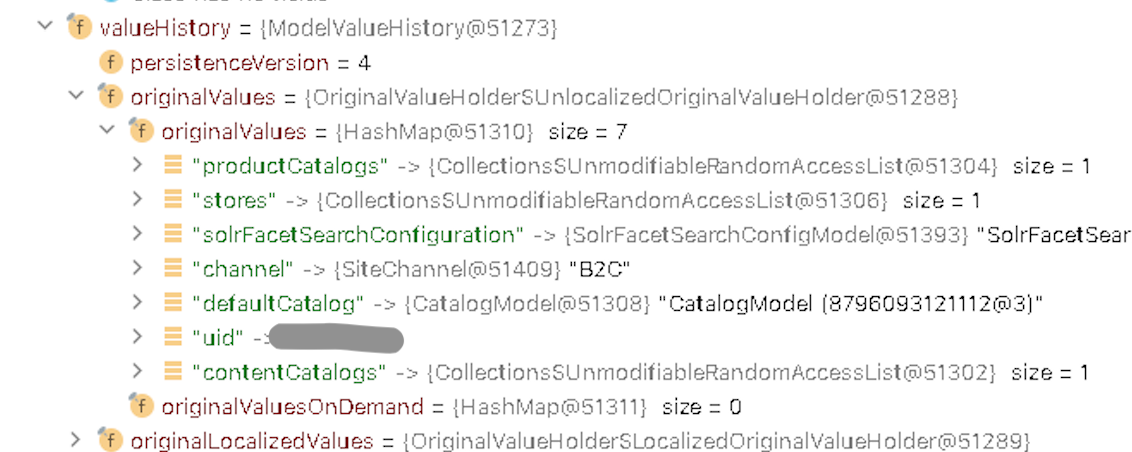
Why?
In fact, original*Values and combined*Attributes can be thought of as caches. They are not populated by default when a model is loaded.
The concept of lazy loading helps SAP Commerce save a lot of memory when big items are fetched from the database for further processing in the code. Only required attributes are loaded into memory, and only when they are explicitly addressed.
Below is a quick experiment to prove it.
Let’s print these before and after modelInstance.getName():
import de.hybris.platform.servicelayer.model.*
import de.hybris.platform.core.*
import de.hybris.platform.store.*
void debugPrint(a) {
println "before a.getName():"
print "combinedLocalizedAttributeValues: ";
println a.getPersistenceContext().combinedLocalizedAttributeValues
print "valueHistory.originalLocalizedValues:"
println a.getPersistenceContext().valueHistory.originalLocalizedValues.toKeys()
println "";
print "calling getName():"
println a.getName()
println "";
println "after a.getName():"
print "combinedLocalizedAttributeValues: ";
println a.getPersistenceContext().combinedLocalizedAttributeValues
print "valueHistory.originalLocalizedValues:"
println a.getPersistenceContext().valueHistory.originalLocalizedValues.toKeys()
println "";
}
pk = ((BaseStoreModel) flexibleSearchService.search("select pk from {BaseStore}").getResult().get(0)).getPk();
println "GET ITEM BY PK"
a = ((ModelService) Registry.getApplicationContext().getBean("modelService")).get(pk)
debugPrint(a)Output:
GET ITEM BY PK
before a.getName():
combinedLocalizedAttributeValues: [:]
valueHistory.originalLocalizedValues:[]
calling getName():Marketplace
after a.getName():
combinedLocalizedAttributeValues: [name:[en:Marketplace]]
valueHistory.originalLocalizedValues:[<en,name>]We see that the data structures were empty before accessing getName, and they were populated after accessing it. For how long? What if we reload this item from the database?
Now let’s append the following code:
b = flexibleSearchService.search("select pk from {BaseStore} where {pk} = "+pk.longValue).getResult().get(0)
println("FLEXIBLESEARCH QUERY")
debugPrint(b)This code reloads this item and assigns it to a different variable, b. Do we expect empty structures there again?
Output:
GET ITEM BY PK
before a.getName():
combinedLocalizedAttributeValues: [:]
valueHistory.originalLocalizedValues:[]
calling getName():Marketplace naftacore
after a.getName():
combinedLocalizedAttributeValues: [name:[en:Marketplace naftacore]]
valueHistory.originalLocalizedValues:[<en,name>]
FLEXIBLESEARCH QUERY
before a.getName():
combinedLocalizedAttributeValues: [name:[en:Marketplace naftacore]]
valueHistory.originalLocalizedValues:[<en,name>]
calling getName():Marketplace naftacore
after a.getName():
combinedLocalizedAttributeValues: [name:[en:Marketplace naftacore]]
valueHistory.originalLocalizedValues:[<en,name>]We see that the values of combinedLocalizedAttributeValues and originalLocalizedValues have retained their values from the previous retrieval. If you request the same object several times in SAP Commerce, the cached version is updated.
We see that the item is cached in memory regardless of how it was fetched from the database: by PK or via FlexibleSearch. If you print out a and b, you will see that these are the same object, although they were fetched in different ways.
If we inject the following before FLEXIBLESEARCH QUERY:
modelService.modelContext.clear()the output will change:
GET ITEM BY PK
before a.getName():
combinedLocalizedAttributeValues: [:]
valueHistory.originalLocalizedValues:[]
calling getName():Marketplace naftacore
after a.getName():
combinedLocalizedAttributeValues: [name:[en:Marketplace naftacore]]
valueHistory.originalLocalizedValues:[<en,name>]
FLEXIBLESEARCH QUERY
before a.getName():
combinedLocalizedAttributeValues: [:] // <--HERE
valueHistory.originalLocalizedValues:[] // <--HERE
calling getName():Marketplace naftacore
after a.getName():
combinedLocalizedAttributeValues: [name:[en:Marketplace naftacore]]
valueHistory.originalLocalizedValues:[<en,name>]Why did we have some attributes in the debug window then? Because this object was used in the same session before, and the cached version contained some attributes. These attributes could be accessed in the MVC filters or when SAP Commerce started.
serializationStrategy
Basically, there is only one option you will see: SerializationStrategyLeanImpl. The alternative, SerializationStrategyDefaultImpl, was deprecated a long time ago, since v6.2.
The serializationStrategy allows you to customize how objects are serialized and deserialized by providing your own implementation of the SerializationStrategy interface. This interface defines methods for serializing and deserializing objects, as well as for encoding and decoding binary data.
By default, SAP Commerce uses a standard serialization strategy based on Java’s built-in serialization mechanism. However, this strategy has some limitations, such as being inefficient and not supporting cross-language interoperability. By implementing a custom serialization strategy, you can overcome these limitations and provide a more efficient and flexible solution that meets your specific needs.
Overall, the serializationStrategy is an important feature for customizing how objects are serialized and deserialized in SAP Commerce/Hybris, and it can be used to improve performance, reduce network traffic, and enable cross-language interoperability.
fetchStrategy
It is normally set to DefaultFetchStrategy.
The DefaultFetchStrategy is the default strategy used by the system. Internally, it responds false to all needFetch(..) calls. In the model context class, the code checks whether the attributes are not loaded yet, meaning they are not in valueHistory.originalValues (see below), and not “dirty” — set but not persisted (see below). If yes, it reloads them from the database.
On the other hand, FetchAlwaysReferencesStrategy is a more aggressive strategy that loads all references as well. The loaded references are not saved to valueHistory.originalValues.
The difference between these two strategies is primarily related to performance and memory usage. DefaultFetchStrategy is more efficient and requires less memory because it loads only the minimum amount of data required to create the item. However, I’ve never seen anyone use it in practice.
valueHistory
The item model’s initial loaded values are recorded and tracked here, along with information about which fields were set.
persistenceVersion is used to track changes to an item in the system. It is a version number that is incremented every time the item is modified and saved to the database.
This attribute serves two main purposes:
- Optimistic Locking: The
persistenceVersionattribute is used to implement optimistic locking, a concurrency control mechanism that prevents simultaneous updates to the same data from corrupting the database. When a user requests to modify an item, the system checks thepersistenceVersionattribute of the item against the one in the database. If they match, the update is allowed, andpersistenceVersionis incremented. If they don’t match, it means that the item has been updated by another user, and the system will prevent the update. - Audit Trail: The
persistenceVersionattribute can be used to track changes to an item over time. By examining the value of thepersistenceVersionattribute, you can see how many times the item has been modified and when those modifications occurred. This information can be useful for auditing purposes or for debugging issues related to data changes.
originalValues is a HashMap similar to combinedAttributeValues. It has a collection of key/value attributes. originalLocalizedValues is the map for localized attributes.
After the value of an attribute is loaded from the database, this map is updated accordingly. At the same time, the value is removed from the list of “dirty” attributes.
The dirtyAttributes property is a collection that contains the names of all attributes that have been modified for a particular item instance. Similarly, the dirtyLocalizedAttributes property is used to track changes to localized attributes.
The purpose of these properties is to provide a way to determine which attributes have been modified so that the system can save only those attributes to the database. This helps to optimize performance by reducing the amount of data that needs to be saved to the database.
When an item is modified, the system automatically updates the dirtyAttributes and dirtyLocalizedAttributes properties to reflect the changes. When the item is saved to the database, only the modified attributes listed in these properties are updated.
In addition, the dirtyAttributes and dirtyLocalizedAttributes properties can be useful for auditing purposes or for debugging issues related to data changes. By examining these properties, you can see which attributes have been modified and when those modifications occurred.
When an item is validated, the system checks its attributes against various validation rules, such as data type, length, or format. If any of these rules are not met, an error is generated for the corresponding attribute. The attributeErrors property is a map that contains the names of the attributes that have errors and the error messages associated with them.
The purpose of attributeErrors is to provide a way to report validation errors to the user or to handle them programmatically. For example, if a user is filling out a form and submits it with invalid data, the system can use the attributeErrors property to display error messages next to the corresponding fields, indicating what needs to be corrected. Alternatively, if the system is processing data programmatically, it can use the attributeErrors property to handle errors and take appropriate actions, such as logging the errors, rolling back the transaction, or notifying the user.
Specifically, attributeErrors is a map of qualifier to exception. The exception here is what is thrown when PersistenceObject.readRawValues is performed against the qualifier.
The purpose of locAttributeErrors is similar to that of attributeErrors, in that it provides a way to report validation errors related to localized attributes to the user or to handle them programmatically.
The valueHistory.listener is a feature that allows tracking changes made to the attributes of an item. When valueHistory.listener is enabled for an item type, the system automatically tracks changes made to the values of the attributes of the item. This tracking is done by creating a ValueHistoryEntry object for each modified attribute, which contains information such as the old value, new value, and the time of the change.
The purpose of valueHistory.listener is to provide an audit trail of changes made to an item, which can be useful for debugging, auditing, or compliance purposes. By examining the ValueHistoryEntry objects, you can see the history of changes made to an item, including who made the changes and when they were made.
This listener is normally set to the adapter class, which proxies the changes to the model context class. The model context class, in turn, updates the internal caches (_modifiedOnes, _loadedOnes) to keep the information about the item consistent.
attributeProvider contains the same attribute provider class as the model context class; see below.
attributeProvider
This class provides an implementation of getAttribute(qualifier), getLocalizedAttribute(qualifier), getPersistentObject(), and getConverter() for the item.
locProvider
This class provides access to the current localization.
dynamicAttributesProvider
This class provides an implementation of a getter and a setter for a dynamic attribute. Normally, it is done via a DynamicAttributeHandler defined per attribute.
Conclusion
So, we’ve established that, in memory, objects initially occupy the same amount of space regardless of the complexity of the model. You can have twenty fields or two hundred, and the overall size of the element won’t reflect the number of fields until you start accessing them. This applies both when accessing the object by PK and when querying the database through FlexibleSearch. During access, a “cache” is filled, which is part of the object, and this cache tends to grow if the object is actively used. If all fields are accessed in the code, the size of the object will grow to a volume dependent on the number of fields and their size. However, it’s possible to reset this cache, thereby reducing the occupied space.
We also figured out that there is no straightforward way to display all object properties in IntelliJ IDEA except through a special plugin that creates a custom renderer for a specific type. This renderer tells IntelliJ IDEA which fields to display and how. If a new field is added during development, the renderer needs to be recreated; the plugin provides a button for this.