Visual search is one of the latest breakthroughs. It is truly making a mark, especially in the e-commerce arena. In 2017, Pinterest launched a visual discovery tool. Ebay launched image search capabilities for mobile devices. These systems use AI and machine learning, which makes this approach too complex for the simple task of grouping products by color.
When you search for a particular product, words are often not enough to find exactly what you need. Sometimes it is easier to work with products similar to the one you like. This is especially true for fashion e-shops. Wouldn’t it be amazing if you could just show your computer a picture, or click on the current product picture, and say, “Find all products like this”?

“Like this”? The similar-products concept is complex. Images may have the same objects but different backgrounds, or the same background but different objects. For e-commerce, images are normally cleaned of non-relevant noise, but even with that, there are complexities too. Products can be similar because they are in the same category, have similar characteristics, or your customers buy them with the same set of accessories. So, in the example above, the customer asks the system to find products that look like this. However, even with this clarification, a new question comes to the front:
What are “similar-looking products”? It is a tough question as well. The common technique is to create fingerprints for the images and compare these fingerprints. Similar images have similar fingerprints. It reduces the complexity and makes the system able to work with thousands or millions of images. Today we will talk about products that are similar because their pictures are similar. Namely, they have visual similarities, e.g., the predominance of some colors and almost identical color layouts.
There are a lot of algorithms for calculating image fingerprints, and a lot of implementations of these algorithms. Basically, both the simplest systems and complex AI and machine-learning software use the concept of image fingerprints, creating a set of numbers representing an image.
There are many image fingerprint systems available on the market, such as pHash, imgSeek, WindSurf, libpuzzle, ImageTerrier, or LIRE. The great list of such tools is on Wikipedia here. There are different algorithms and implementations. I experimented with the last library from this list, LIRE. Eventually, I needed to integrate it with hybris Search, so it was a big advantage that LIRE has a module for Solr. It greatly helped me create a proof of concept in a short time.
LIRE was released in 2006 under GPL. The name LIRE stands for Lucene Image REtrieval, so it had a good foundation from the very beginning for integrating with Solr, which is based on Lucene. Now LIRE is a stable project with a strong community of contributors. The important feature of LIRE for me is that it is written entirely in Java and can be integrated with SAP Hybris.
However, LIRE has some drawbacks too. It does very rough similarity because it is mostly based upon color usage. It re-ranks the search results retrieved in full (up to 10,000, which is configurable) even if you request only the first ten items, which means that it may work much slower on large datasets than you may expect.
Another product from the list, imgSeek, open source and free, is a good alternative to some degree. It analyzes the images, stores them in its own index, and provides you with a query interface. This will not be integrated with your Solr instance, and you’ll have to do two separate queries. imgSeek uses QT and ImageMagick and is implemented in Python 2.4, so it cannot be integrated into the Hybris search subsystem as well as I wanted.
There are external commercial services, such as Match Engine from TinEye, for example.
Going forward, I will demonstrate the results first:
So, let’s come back to LIRE-Hybris integration. First, let me give you a bit of theory on how similarity and image fingerprints work. It is necessary to understand the details of the integration.
How Image Similarity Works
The common approach of image fingerprinting is representing the image using the minimal amount of information needed to encode its essential properties. This minimal information is called an image descriptor, and the process is known as feature extraction.
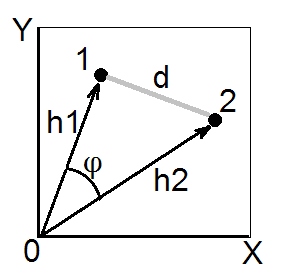
The key idea of the approach is to use a function that maps images into an n-dimensional Euclidean vector space (R^n) such that similar images are mapped to points close to each other and dissimilar images are mapped to points far away from each other. A vector distance such as the simple Euclidean vector distance then provides a similarity metric that can be used to determine which images are more similar to each other. The smaller the distance value, the more similar the images are. To build the result list for our sample application, we just need to sort the array containing all the images in a directory by their distance to the specified search image.
For two dimensions, the distance will look like this:
However, the image cannot be represented efficiently by two dimensions. If we add a third dimension, the distance will be calculated in the same way:
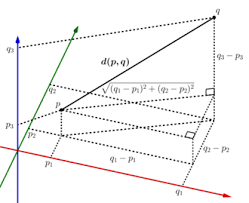
Vectors that represent images are called feature vectors. Feature vectors have many more dimensions. For example, “Color and Edge Directivity” (CED) is 54 bytes long, so it defines a vector in 54-dimensional space, and this vector represents an image. Another popular method is MPEG7 standard image descriptors and FCTH (Fuzzy Color and Texture Histogram). These descriptors have the desired properties: visually similar images are mapped to close points in an n-dimensional vector space.
Optically similar images get assigned similar feature vectors, and optically dissimilar images get assigned very different feature vectors, such that the Euclidean distances between the vectors assigned to the first two images are smaller than the Euclidean distances between the vectors assigned to the first two and the third image. Different algorithms create the vectors differently.
LIRE supports the following feature-vector algorithms:
- MPEG-7 Color Layout (cl).
- Pyramid Histogram of Oriented Gradients, PHOG (ph)
- MPEG-7 Edge Histogram (eh)
- AutoColorCorrelogram (ac)
- Color and Edge Directivity Descriptor, CEDD (ce)
- Fuzzy Color and Texture Histogram, FCTH (fc)
- Joint Composite Descriptor, JCD (jc)
- Opponent Histogram (oh)
- ACCID (ad)
- Fuzzy Opponent Histogram (fo)
- Joint Histogram (jh)
- MPEG-7 Scalable Color (sc)
- SPCEDD (pc)
MPEG-7 Color Layout
Simply put, it represents the spatial distribution of the color in images in a compact form. The image is divided into 8×8 discrete blocks, and their representative average colors in the YCbCr color space are extracted. The descriptor is obtained by applying the discrete cosine transformation (DCT) on every block and using its coefficients. The produced descriptor (=fingerprint) is a 3×64 representation of the image. By the way, image partitioning into blocks, DCT transformation, and zigzag scanning are used in JPG format.

Edge Histogram Descriptor
It represents the spatial distribution of five types of edges in the image. An image is subdivided into 4×4 subimages, and the local edge histogram of five broadly grouped edge types (vertical, horizontal, 45 diagonal, 135 diagonal, and non-directional) is computed. As a result, the descriptor is 4x4x8. So this method is used mainly for describing shape features. For each type of edge, there are corresponding filters.

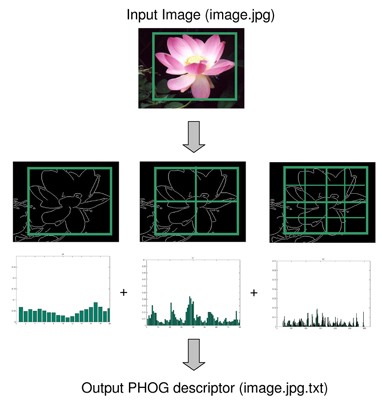
Pyramid Histogram of Oriented Gradients (PHOG)
The technique counts occurrences of gradient orientation in localized portions of an image. This method is similar to that of edge-orientation histograms but differs in that it is computed on a dense grid of uniformly spaced cells and uses overlapping local contrast normalization for improved accuracy.
The essential thought behind the histogram of oriented gradients descriptor is that local object appearance and shape within an image can be described by the distribution of intensity gradients or edge directions. The image is divided into small connected regions called cells, and for the pixels within each cell, a histogram of gradient directions is compiled. The descriptor is the concatenation of these histograms.
Other algorithms
Color Correlogram Algorithm expresses how the spatial correlation of pairs of colors changes with distance. Informally, a correlogram for an image is a table indexed by color pairs, where the d-th entry for row (i,j) specifies the probability of finding a pixel of color j at a distance d from a pixel of color i in this image. An autocorrelogram captures spatial correlation between identical colors only.
Color and Edge Directivity Descriptor Algorithm (CEDD) combines a 24-bin fuzzy color histogram with 6 types of edges (see edge histogram descriptor above). After extraction, the set is normalized and quantized. The result is an overall descriptor length of 54 bytes, so it is compact.
Fuzzy Color and Texture Histogram (FCTH) uses the same fuzzy color scheme as CEDD, but it has a more extensive edge description method. It is also more accurate but less compact than CEDD. A combination of CEDD and FCTH is the Joint Composite Descriptor (JCD). All three are robust to scaling and rotation. Color layout and edge histogram are robust only to scaling.
OpponentHistogram is a simple color histogram in the opponent color space (luminance / red-green / blue-yellow).
Integrating LIRE with Hybris
There are two processes that need to be implemented:
- indexing the images
- creating the image descriptors and adding them to the Solr index along with the products these images belong to
- getting the products that have images similar to X
- configuring Solr to use the descriptors as search criteria
Configuring Solr
- Add a request handler to
config/solr/instances/default/configsets/default/conf/solrconfig.xml, next to the existingrequestHandler name="/select":
<requestHandler name="/lireq" class="net.semanticmetadata.lire.solr.LireRequestHandler">
<lst name="defaults">
<str name="echoParams">explicit
<str name="wt">json
<str name="indent">true
</lst>
</requestHandler>- Add a value source function. This allows ranking based on the distance function. It is added to text-based search queries. For example, it can be used for sorting with the normal
selectquery Solr request.
<valueSourceParser name="lirefunc"
class="net.semanticmetadata.lire.solr.LireValueSourceParser" />- Add the dynamic field definitions and DocValue-based binary field:
<dynamicField name="*_ha" type="text_ws" indexed="true" stored="false"/> <!-- if you are using BitSampling -->
<dynamicField name="*_ms" type="text_ws" indexed="true" stored="false"/> <!-- if you are using Metric Spaces Indexing -->
<dynamicField name="*_hi" type="binaryDV" indexed="false" stored="true"/>- Compile the LIRE library (
gradle distForSolr) and copydist/*.jartohybris/bin/ext-commerce/solrserver/resources/solr/7.4/server/server/solr-webapp/webapp/WEB-INF/lib.
In the last fragment, there are definitions for BitSampling and MetricSpaces. binaryDV is used for storing the feature vectors for different algorithms.
BitSampling is a basic hashing method. It regenerates hashes to save space on the fly instead of storing them in the index.
MetricSpaces is the proximity approach based on the work of Giuseppe Amato. While it’s actually not a hashing routine, it’s an easy way to use it within LIRE. Based on a pre-trained set of representatives, the features of the representatives are stored in a text file. For indexing and search, they can be used to create hash-like text snippets, which are then used to search and index.
Indexing the images
The goal of this process is to enrich the products in Solr with information about the product picture, namely, with the image vector.
In hybris, we need to extend the indexing subsystem to add extra fields to the indexing request.
For the PoC, I extended DefaultIndexer. Add the LIRE library (JAR) to the project (/lib) of your extension. For my extension, I took the code from ParallelSolrIndexer.java (start reading the code from the method run()). The code opens the media file for the product, trims the white space around the product image (ImageUtils.trimWhiteSpace), and downscales the image to 512 pixels as the maximum side length (ImageUtils.scaleImage). For each of the registered global feature algorithms, it adds the dynamic field values to the indexing request:
featureAlgorithmClass.extract(img);
featureAlg = getCodeForClass(featureAlgorithmClass); //cl, eh, jc and phdocument.addField(featureAlg+"_hi", Base64.getEncoder().encodeToString(feature.getByteArrayRepresentation()));document.addField(featureAlg+"_ha", BitSampling.generateHashes(feature.getFeatureVector()));document.addField(featureAlg+"_ms", MetricSpaces.generateHashString(feature));The list of featureAlg is configurable. I used ColorLayout.class, EdgeHistogram.class, JCD.class, and PHOG.class with the featureAlg codes cl, eh, jc, and ph, respectively. The listed classes are part of the LIRE library. So, for 4 algorithms, you will have 12 additional fields in the request.
Search
There are two options:
- Using a designated RequestHandler (
/lireq) - Using a function (
lirefunc)
or both.
For example, the following JSON is returned for the request:
https://localhost:8983/solr/master_apparel-uk_Product_default/lireq?id=apparelProductCatalog/Online/300147493&fl=id,d&field=cl_ha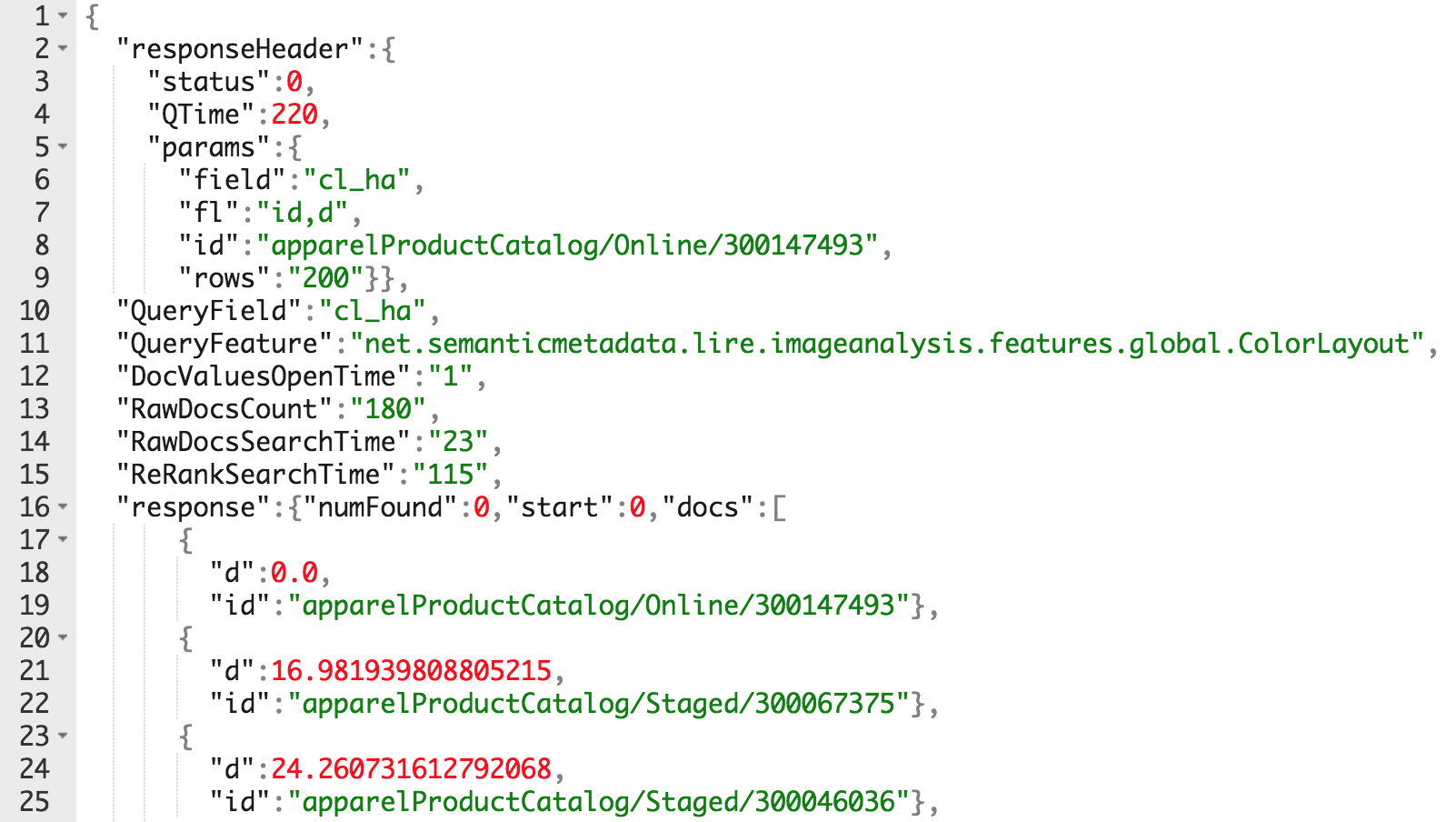
You can parse it and show it with the custom recommended-products component.
The request above is not standard; it uses a separate request handler (/lireq).
Using a designated request handler
The LIRE request handler supports the following operations:
- get images that look like the one
- having the specific ID
- found at URL
- get images with a feature vector
- extract histogram and hashes from an image URL
The request handler re-ranks the results received from Solr. If you request the first five products, internally it will request Solr for a much larger amount (by default, 10,000 candidates), re-rank them, and trim the results to the specified value (in rows).
Using lirefunc
The lirefunc function can be used together with a standard select request, which is normally used by hybris.
The function lirefunc(arg1,arg2) is available for function queries. Two arguments are necessary and are defined as:
- Feature to be used for computing the distance between result and reference image. Possible values are
{cl, ph, eh, jc} - Actual Base64-encoded feature vector of the reference image. It can be obtained by calling
LireFeature.getByteRepresentation()and Base64 encoding the resultingbyte[]data, or by using the extract feature of theRequestHandler - Optional maximum distance for data items that cannot be processed, i.e., that don’t feature the respective field
Note that if you send the parameters using a URL, you might need to take extra care with the URL encoding, i.e., white space, the = sign, etc.
Examples:
[solrurl]/select?q=*:*&fl=id,lirefunc(cl,”FQY5DhMYDg…AQEBA=”)– adding the distance to the reference image to the results[solrurl]/select?q=*:*&sort=lirefunc(cl,”FQY5DhMYDg…AQEBA=”)+asc– sorting the results based on the distance to the reference image
With this option, I faced an issue: lirefunc deals only with items returned by select. If it is a small subset of all items, the results won’t be sorted properly. I hope it is a misconfiguration on my side.
Performance
For large sets of images, the solution above may be too slow because of per-request processing of all images. Possibly, you want to pre-calculate the recommendations (products of the same color) to make it much faster. However, for the generic task, the performance issues are inevitable if your dataset is getting bigger and bigger, even with such optimization techniques as locality-sensitive hashing, which is used in the current solution (BitSampling).
Secondly, you need to double-check what feature vectors are really important for you to have in the index. Each additional vector may add gigabytes to the index size and, as a result, slow down both indexing and searching.
Thirdly, this task can be solved with machine-learning algorithms too, with the use of enhanced algorithms for feature extraction, such as SURF and SIFT. However, this has to be left for another day.
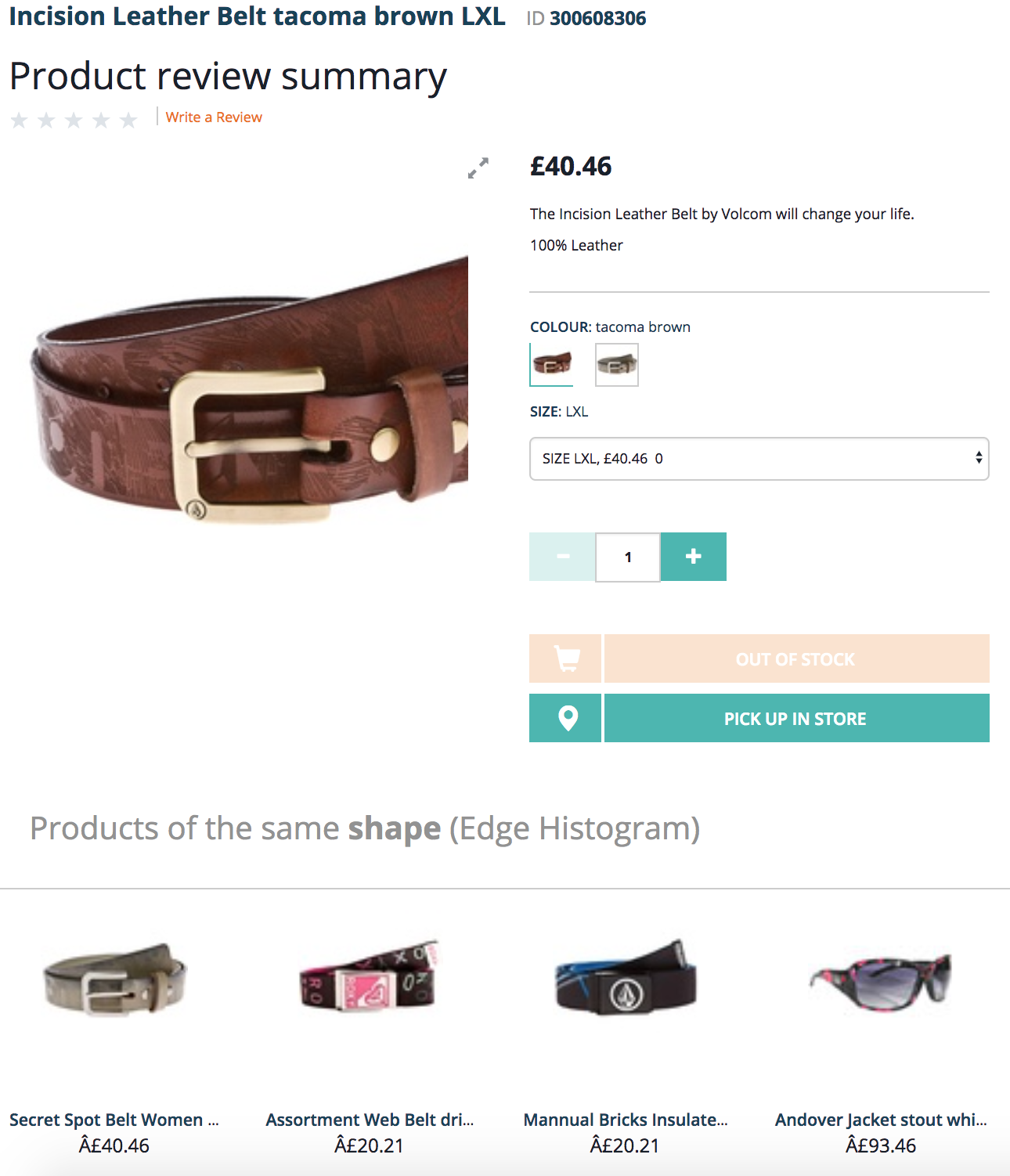
PoC screenshots
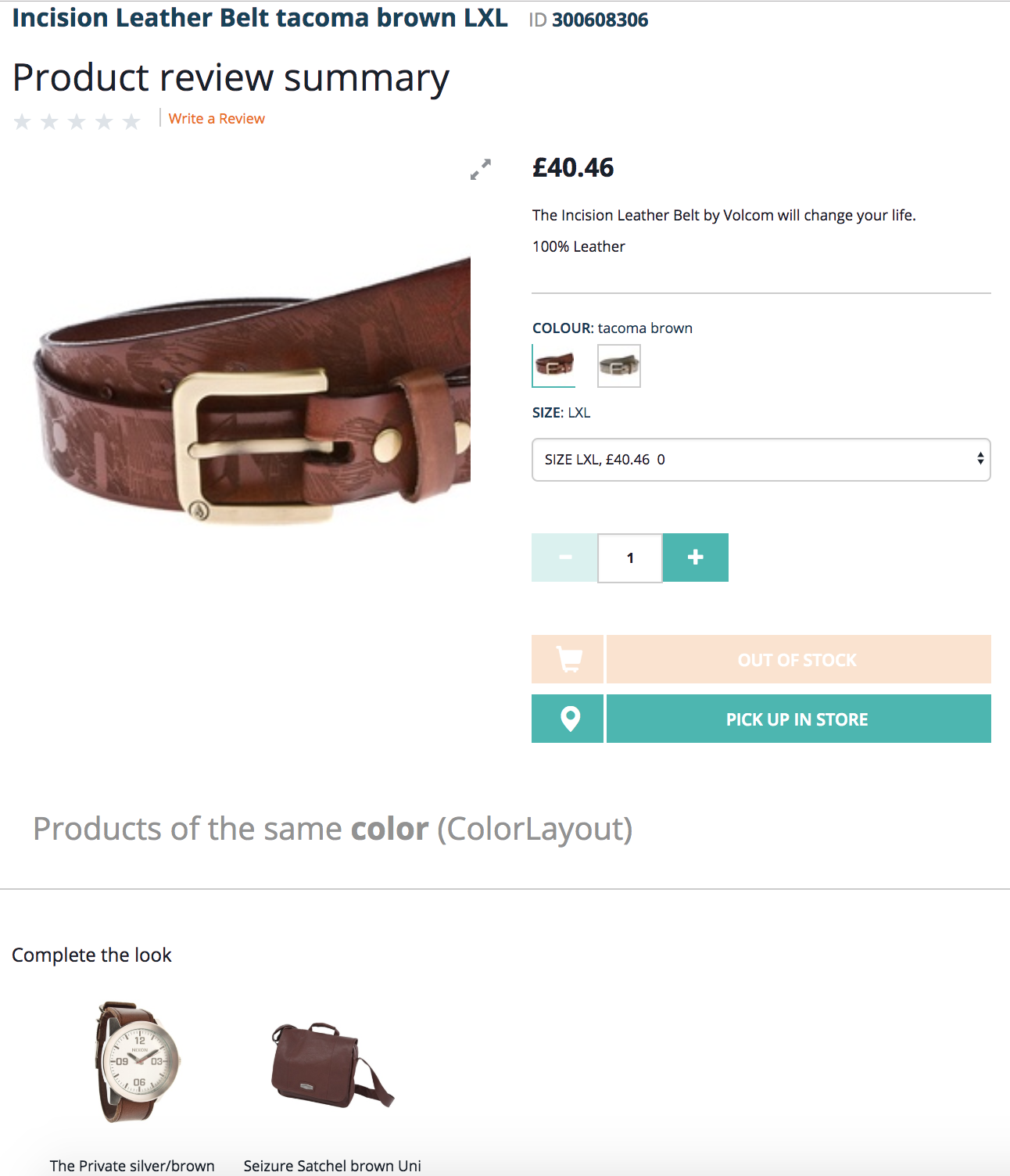
Color Layout: The products with similar color histograms



Edge Histogram: Products with similar shape

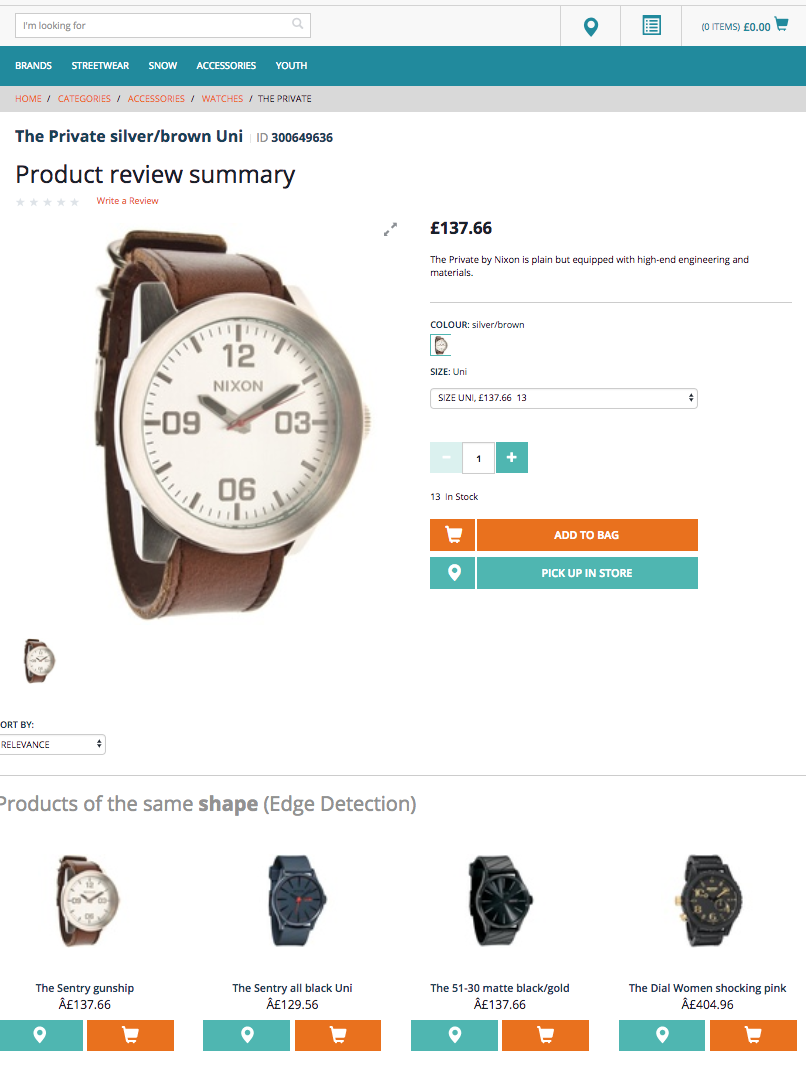
When the product catalog is small or the color cluster is small, the system shows the best possible match (the fourth product is not a belt).