
This article began with a simple question: why does the search query “camera lenses” lead to tripods in the Electronics SAP Hybris demo storefront rather than camera lens products, when we have a category named “camera lenses” and a product with “Lens” in its name? Try it yourself!
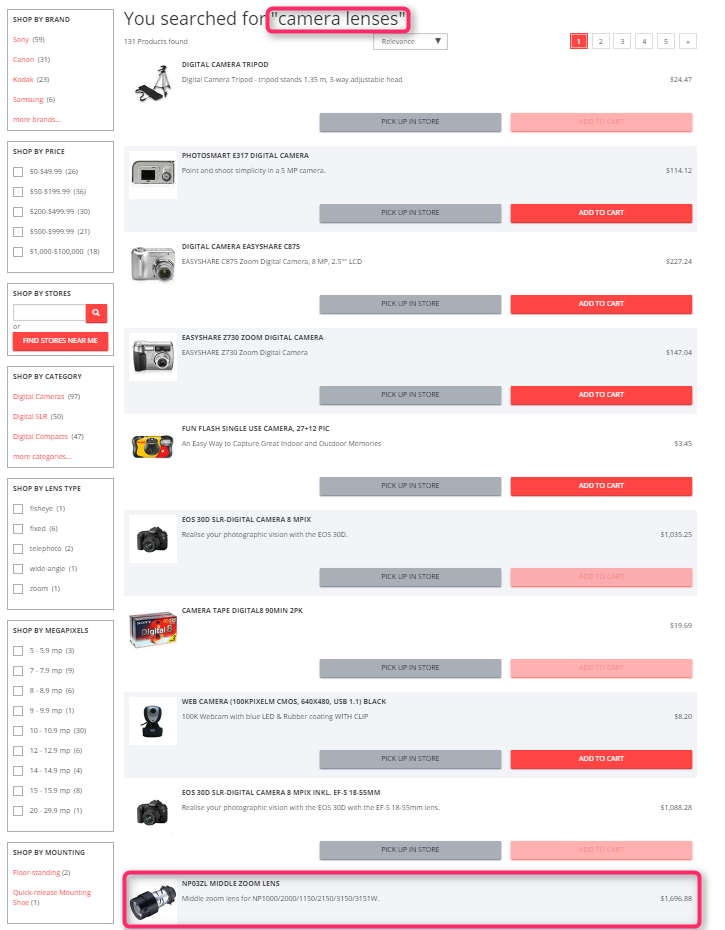
The first relevant product is in 10th position! This is the case despite the fact that some products have the words from the query both in the description and in the category name, such as the following one:
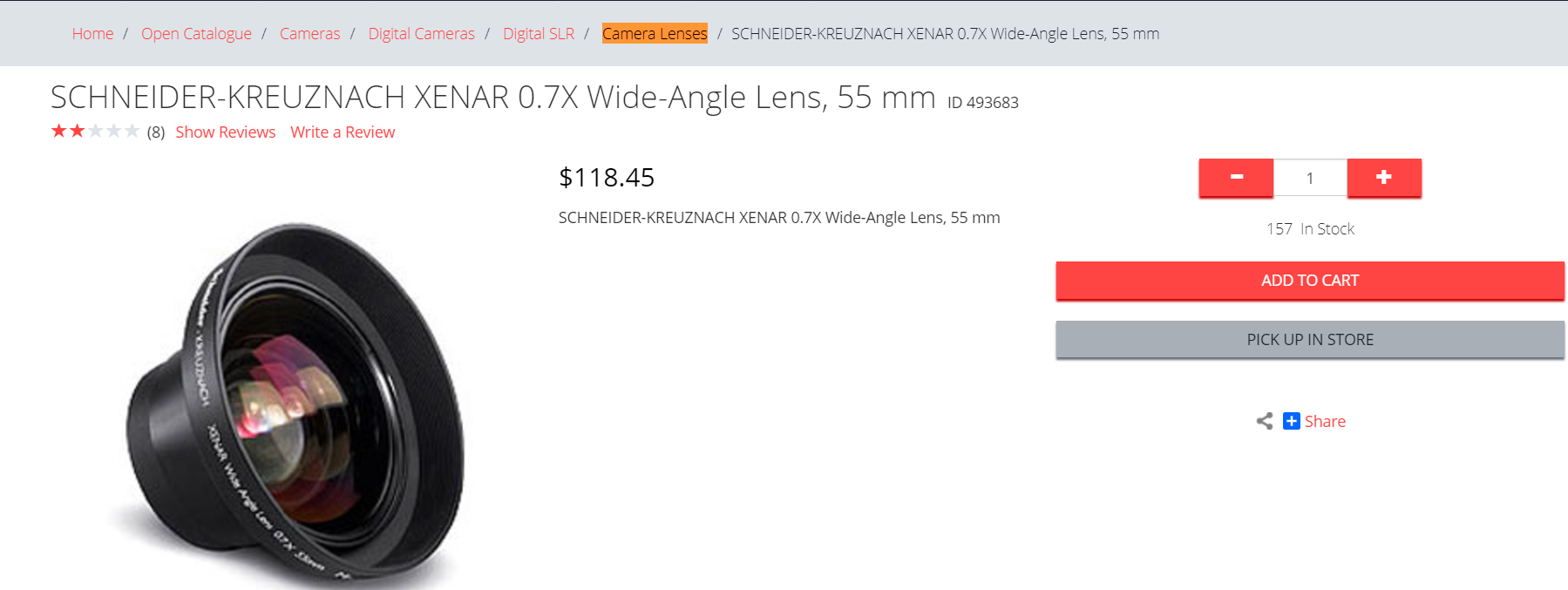
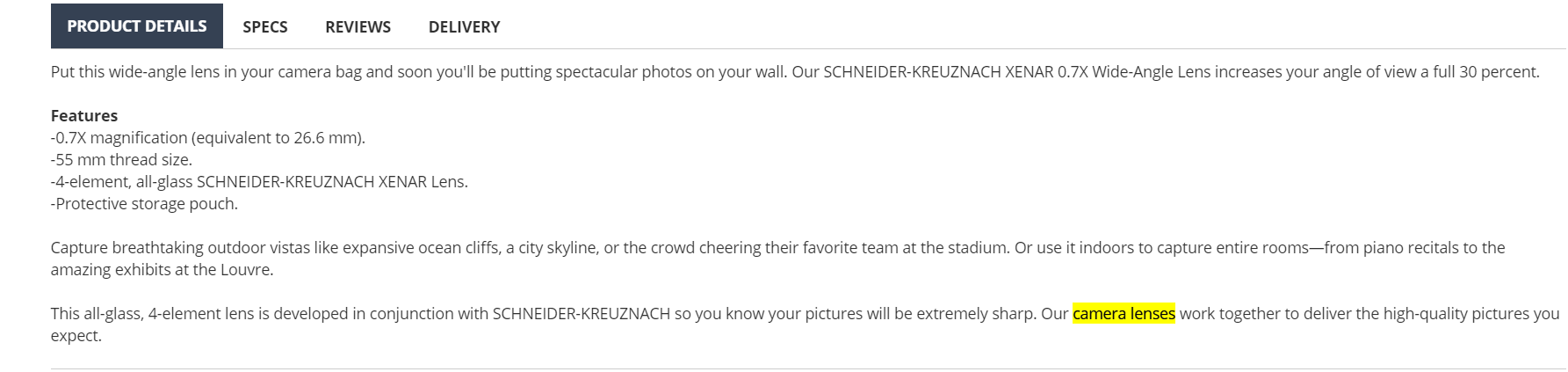
In addition to that, this product has “Lens” in the title, which should make it even higher in the search results since we state that the search supports different word forms.
In this article, I will explain why this is happening.
Hybris and Solr Integration
Hybris uses Solr for product search. For every user search request and some navigation requests, Hybris calls the search engine.
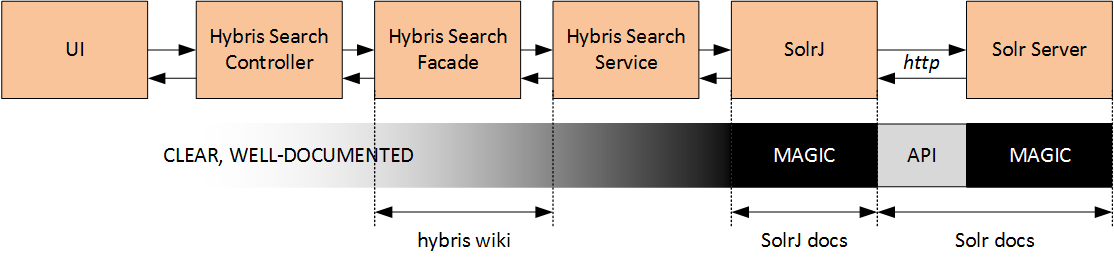
There are three interfaces between Hybris and Solr:
- Indexing
- Search
- Autosuggest and spellcheck
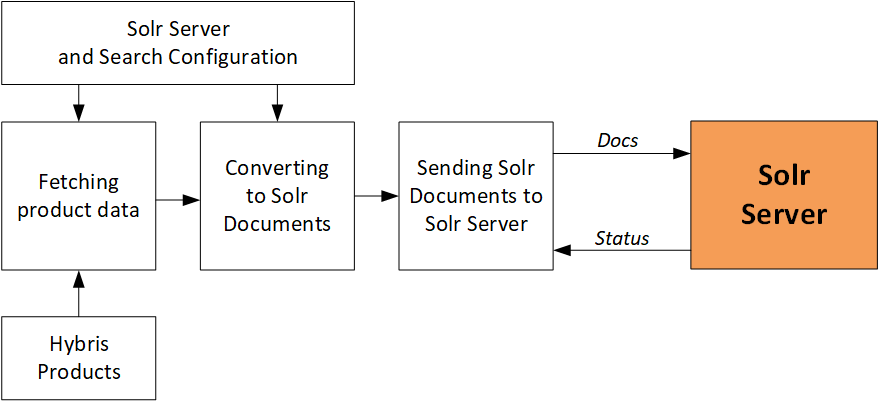
Indexing
Hybris fetches data from the database, converts it into SolrJ documents, and sends it to Solr Server in batches of 100 documents each. There are overridable listeners executed before and after batches. There are also listeners before and after the whole indexing process. Full indexing recreates the index. For update mode, only new and changed products are processed.
Search
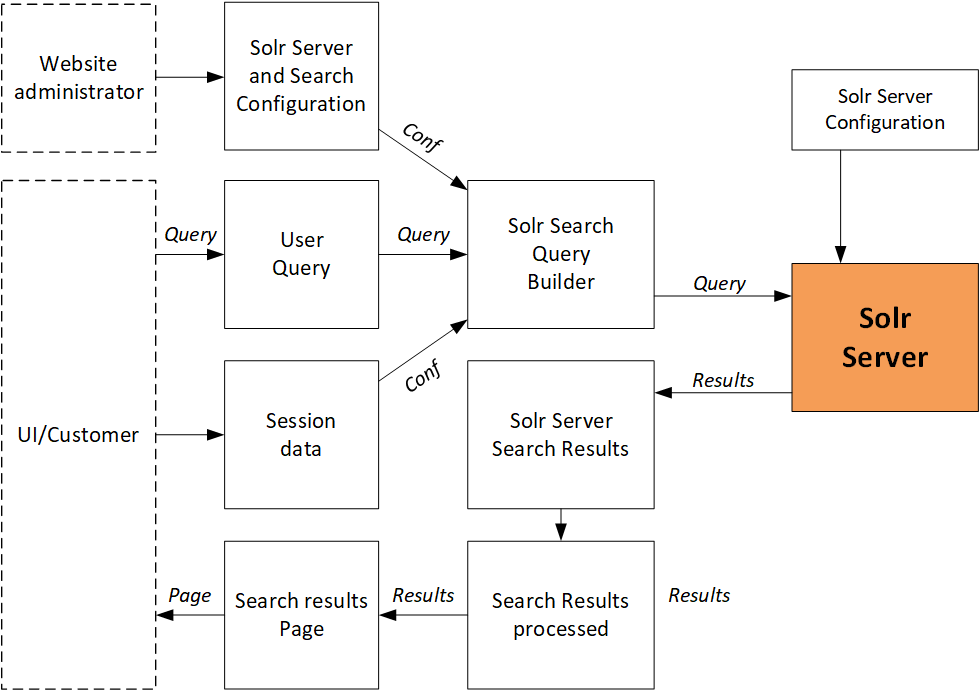
For search, the system converts the customer search query into a Solr search query.
Autosuggest
Autosuggestion/autocomplete is built on the spellcheck functionality. Solr has a Suggester component specially designed for this purpose, but for some reason Hybris decided to go with the old reliable spellcheck component.
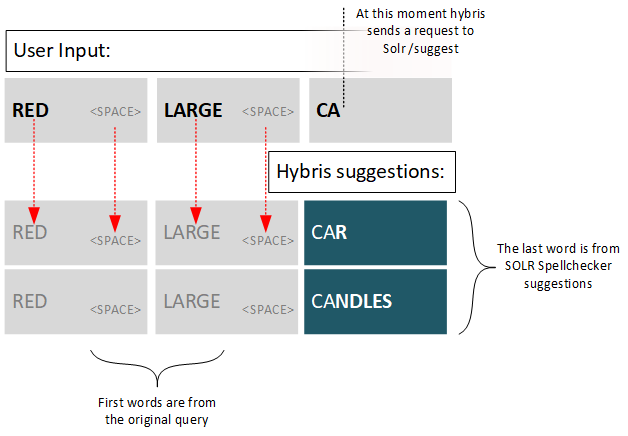
How does Hybris find words for “CA…”? There is a Solr multivalued field called autosuggest (and its language versions, autosuggest_) of the text_spell type. This type is defined as Solr’s standard TextField type. It contains lowercased tokens (words) from the product attributes configured as “autosuggest” indexed properties.
Spellcheck
Spellchecking uses a similar Solr interface. For spellcheck fields, Hybris uses a different set of product attributes.
* * *
However, there are grey areas that are not well documented. For example, for a single-word request, Hybris generates a comprehensive multi-line query containing various filters and conditions. Understanding this mechanism is crucial for troubleshooting, solutioning, and customization.
Solr logs help you understand the real queries generated by Hybris. For the default installation, the logs are here:
hybris\log\solr\instances\default\solr.log[!!!!] The explanation below is relevant for the default Lucene query parser, the default Hybris configuration, and version 6.4 of Hybris Commerce. LuceneQParser is used only with the OOTB Multi Field Free Text Query Parser. See this article for explanations of the differences. Configuration changes may lead to different queries and ranking.
The simple request “keyword” leads to the following Solr request, or something similar, depending on the Solr configuration:

Each line represents a condition. The number at the end is a boost factor used in the relevancy calculation. The boost factor is used to increase or decrease the importance of the filter in the query. Below I will show how this value is used in the relevancy calculation for search result ranking.
The Solr query for the sample query
kw1 kw2will look like this:
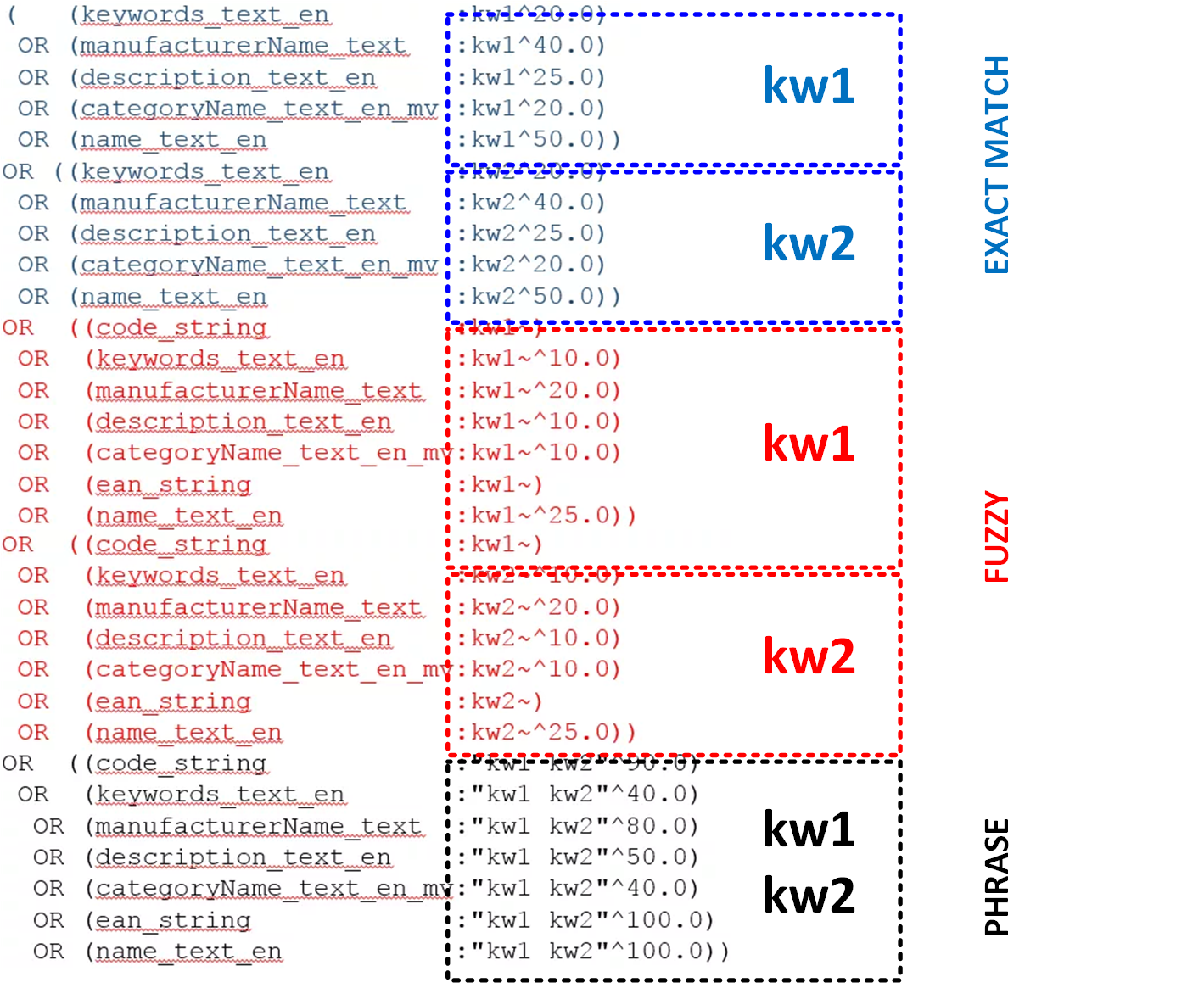
For three or more words, the search request has a condition for the whole set of words as a single phrase. For example, for the request “kw1 kw2 kw3”, the “black” section contains three words, and the blue and red sections have:
kw3For multi-word requests, only a whole phrase will affect the relevancy:
(...single word conditions ...)
...
OR ((code_string:"kw1 kw2 kw3 kw4"^90.0)
OR (keywords_text_en:"kw1 kw2 kw3 kw4"^40.0)
OR (manufacturerName_text:"kw1 kw2 kw3 kw4"^80.0)
OR (description_text_en:"kw1 kw2 kw3 kw4"^50.0)
OR (categoryName_text_en_mv:"kw1 kw2 kw3 kw4"^40.0)
OR (ean_string:"kw1 kw2 kw3 kw4"^100.0)
OR (name_text_en:"kw1 kw2 kw3 kw4"^100.0))"
...You may expect that for the request “compact Sony cameras”, the subphrases “compact Sony” and “Sony cameras” will be taken into account by the search engine and affect the relevancy. This is not so: only the whole phrase “compact Sony cameras” is considered as a phrase having specific boost factors.
Search Ranking in Hybris
Fine, now we are at the best part. Why are lenses in 10th position?
Look at the queries above. They have some magic numbers after the “^” sign. These numbers are boost factors. You can change them for any indexed field in Backoffice. Specifically, there are four boost factors used in the queries:
- Single keyword full-text search boost factor (
ftsQueryBoost) - Phrase query boost factor (
ftsPhraseQueryBoost) - Fuzzy query boost factor (
ftsFuzzyQueryBoost) - Wildcard query boost factor (
ftsWildcardQueryBoost)
In our example above, the first three are used. Wildcards are off in the default search template configuration, so they don’t work in this example. Each field has its own set of boost factors. For example, for the Electronics demo storefront, there is a default boost configuration:
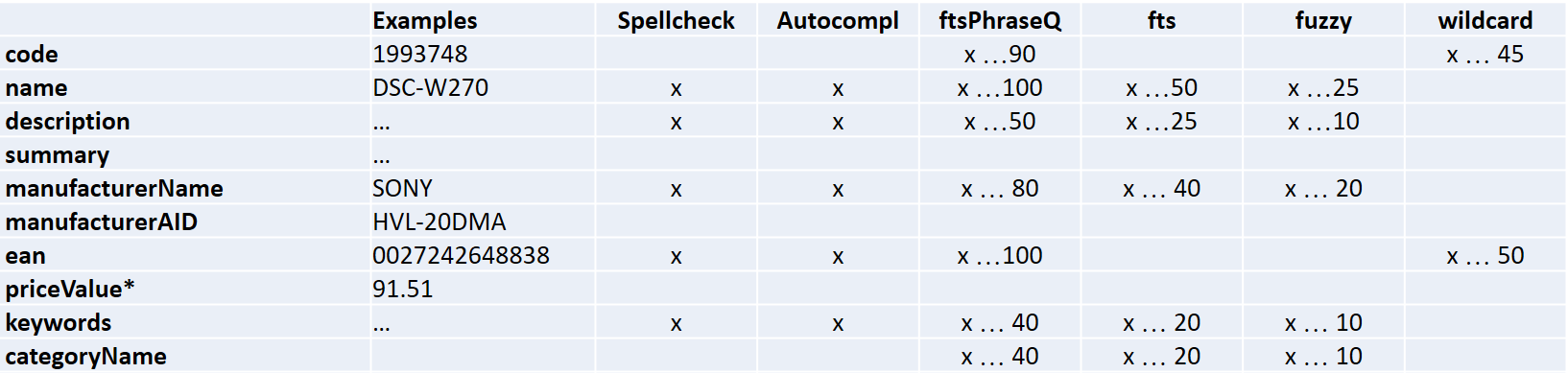
This configuration says, for example, that
codeis involved in the phrase search, but it is not involved in a single keyword search. It means that if your query has nothing but the code, the boost factor 90 will be applied to your request. That is #2 after the exact name and exact EAN.
So there are two intertwined phases, or processes, in the search engine: fetching relevant results and sorting them. Look at the conditions again: all of them are joined by ORs. Once any condition is true, the product will be included in the search results, but possibly far from the beginning.
In reply to my query, “camera lenses”, I got a number of products in an unexpected order. According to the Hybris search engine, with the default configuration — not the best one — “Monopod 100” has overtaken “Schneider-Kreuznach Xenar 0.7X Wide Angle Lens, 55mm”, which seems much more relevant.
Query:
camera lenses| Monopod 100 | Schneider-Kreuznach Xenar 0.7X Wide Angle Lens, 55mm | |
|---|---|---|
| description: | *“Canon Monopod 100 for SLR Cameras & Lenses“* | Put this wide-angle lens in your camera bag and soon you’ll be putting spectacular photos on your wall. Our SCHNEIDER-KREUZNACH XENAR 0.7X Wide-Angle Lens increases your angle of view a full 30 percent. Features -0.7X magnification (equivalent to 26.6 mm). -55 mm thread size. -4-element, all-glass SCHNEIDER-KREUZNACH XENAR Lens. -Protective storage pouch. Capture breathtaking outdoor vistas like expansive ocean cliffs, a city skyline, or the crowd cheering their favorite team at the stadium. Or use it indoors to capture entire rooms—from piano recitals to the amazing exhibits at the Louvre. This all-glass, 4-element lens is developed in conjunction with SCHNEIDER-KREUZNACH so you know your pictures will be extremely sharp. Our camera lenses work together to deliver the high-quality pictures you expect. |
| categoryName: | *“Digital SLR”, “Cameras”, “Tripods”, “Open Catalogue”, “Digital Cameras”* | “Cameras”, “Digital SLR”, “Digital Cameras”, “Camera Lenses”, “Open Catalogue” |
Both products have both keywords in two fields: categoryName and description. All other fields are either not mentioned in the request or do not contain any of the keywords.
At this point, it should be clear how the search engine solves the first task: understanding what products have to be included in the response.
The next phase is ranking these products and displaying them ordered by relevancy.
For each document, relevancy is calculated as a sum (only for one query builder in Hybris; read here for details) of relevancy components corresponding to the specific conditions. For example, for the query above, we should sum up the following components:
| Monopod 100 | Schneider-Kreuznach Xenar 0.7X Wide Angle Lens, 55mm | |
|---|---|---|
| Exact match check: | ExactScore (“camera” in description, “camera” in categoryName) | ExactScore (“camera” in description, “camera” in categoryName) |
| ExactScore (“lens” in description) | ExactScore (“lens” in description, “lens” in categoryName) | |
| Fuzzy match check: | FuzzyScore (“camera” in description, “camera” in categoryName) | FuzzyScore (“camera” in description, “camera” in categoryName) |
| FuzzyScore (“lens” in description) | FuzzyScore (“lens” in description, “lens” in categoryName) | |
| Phrase match check: | PhraseScore (“camera lens” in description) | PhraseScore (“camera lens” in description, “camera lens” in categoryName) |
Actually, all three score formulas are the same. The only difference is a score factor, which can be different for phrase, fuzzy, and exact matches per field.
Solr has a debug flag that shows the scores behind the results. In order to see the scores for this request, you should:
- Extract the Solr request from the Solr log
- Perform this request in Solr with debug on
- Find the score calculation in the response along with the search results
| Monopod 100 TOTAL SCORE=401.42 |
Schneider-Kreuznach Xenar 0.7X Wide Angle Lens, 55mm TOTAL SCORE=238.97 |
|
|---|---|---|
| Exact match check: | ExactScore=46.493 (=max of “camera” in description (46.493), “camera” in categoryName (7.6)) | ExactScore=35.191 (=max of “camera” in description (35.191), “camera” in categoryName (9.02)) |
| ExactScore=76.045 (=max of “lens” in description (76.045)) | ExactScore=48.828 (=max of “lens” in description (39.926), “lens” in categoryName (48.828)) | |
| Fuzzy match check: | FuzzyScore=18.597 (=max of “camera” in description (18.597), “camera” in categoryName (3.84)) | FuzzyScore=14.076 (=max of “camera” in description (14.076), “camera” in categoryName (4.511)) |
| FuzzyScore=15.209 (=max of “lens” in description (18.597)) | FuzzyScore=12.207 (=max of “lens” in description (7.985), “lens” in categoryName (12.207)) | |
| Phrase match check: | PhraseScore=245.077 (max of “camera lens” in description (245.077)) | PhraseScore=128.673 (=max of “camera lens” in description (128.673), “camera lens” in categoryName (108.335)) |
The total score of Monopod is higher, and this is why its position is higher in the search results. But how are these scores calculated? What gives Monopod the win?
The answer is “all scores”:
- The total exact score of Monopod is higher than the same score for the lens
- The total fuzzy score is also higher
- The total phrase score is also higher
There are different ways to calculate scores. Hybris uses Solr 6, which is based on the latest Lucene, which uses the BM25 ranking algorithm by default. So below I will explain the details of this algorithm.
Before answering each of these questions, let’s look at the score formula:
- Total Score = Sum(Scores)
- Where Score = Boost * TF * IDF
- Where TF is normalized term frequency: how often the term occurs in the document.
- Where IDF is inverse document frequency: how special or rare the term is, and how many documents a term appears in. “Inverse” means the following: very frequent terms have smaller IDF values.
We see that the phrase score makes the most significant contribution to the total score. Let’s take this score as an example and deep dive into the details of the calculation.
- Original request: “camera lenses”
- Results:
- Monopod, TOTAL SCORE=401.42
- Lens, TOTAL SCORE=238.97
- The most influential component is “camera lens” in description
- Score = Boost * function(TF, IDF)
The phrase boosting factor (“Boost”) is, as shown in the table above, 50 for the description field. This value is the same for both products because it doesn’t depend on the product. It depends only on the field; in both cases it is description.
=> Boost = 50 for both products.
This value is editable via Backoffice for the fields. Hybris AdaptiveSearch can personalize boosts for whole categories and products. Hero products are products with a very high boost factor.
The inverse document frequency (IDF) is a measure of how much information the word provides: that is, whether the term is common or rare across all documents. IDF is computed as:
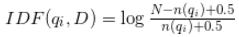
where n(qi) is the number of documents containing a word qi, and N is the total number of documents. In our example, N = 340.
For “camera”: qi = 108 documents. IDF("camera") will be 1.15.
For “lenses”: qi = 52 documents. IDF("lenses") will be 1.87.
IDF = IDF(“camera”) + IDF(“lenses”) = 1.15 + 1.87 = 3.02.
=> IDF = 3.02 for both terms.
For the phrase “camera lenses”, IDF is calculated as a sum of IDF("camera") and IDF("lenses"), and does not depend on the number of documents containing the whole phrase.
The term frequency is a simple factor. The more frequently a term occurs in a document, the greater its score. Documents with twice the number of terms as another document aren’t twice as relevant:
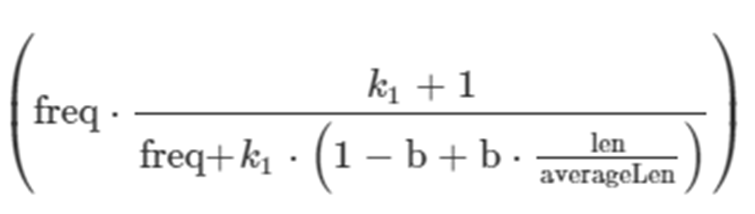
where:
- freq is term frequency in the document = 1 for both cases, because the phrase “camera lenses” is used once per document
- k1 is a constant;
k1 = 1.2 - b is a constant;
b = 0.75 - len is the length of the field
- averageLen is the average length of this field across all records
The length to average length ratio is important. A topic occurring twice in your website pages says almost nothing about how much this website is about the topic. The same topic occurring twice in a short tweet, however, means that tweet is very much about it.
The average length in our example is 115.01.
For Monopod 100, the length of the description is 42 characters: “Canon Monopod 100 for SLR Cameras & Lenses”. Actually, fieldLength is not simply the number of characters the field contains. It is calculated via a complicated mathematical normalization encoding/decoding equation, basically compressing 32-bit integers to 8 bits to save disk space while storing the data.
The normalized term frequency for our example is different for the products:
| Monopod 100 | Schneider-Kreuznach Xenar 0.7X Wide Angle Lens, 55mm |
|---|---|
| freq=1 | freq=1 |
| k1=1.2 | k1=1.2 |
| b=0.75 | b=0.75 |
| average Field Length=115.01 | average Field Length=115.01 |
| len = 42 (before normalization) | len = 826 (before normalization) |
| TF Norm = 1.6228 | TF Norm = 0.8520 |
It turned out that the short description for Monopod 100 makes the term frequency higher and eventually gives the product a higher position.
This explains Monopod’s higher exact match, fuzzy match, and phrase match scores. Because this field is shorter, and the ratio len/averageLen is large, TFNorm is larger, and consequently, the whole score is larger.
Certainly, other scores also contributed, but their contribution to the final score is smaller.
By the way, we have a category with the name “Camera Lenses”, which is exactly what we looked for. From the business perspective, all products from this category should be higher. However, the categoryName field has smaller boost factors than the description field:

Score(categoryName contains “camera lenses”) = (Boost40 * IDF3.17 * TFNorm0.85) = 108.33
Score(description contains “camera lenses”) = (Boost50 * IDF3.01 * TFNorm0.85) = 128.49
Lens in the Name?
You may ask: what about “Lens” in the name? Why doesn’t it take it into account? We see that “Lenses” is a plural form of “lens”, and the search has a stemming filter that is able to process word forms. Indeed, yes and no.
The name of the product, “Schneider-Kreuznach Xenar 0.7X Wide Angle Lens, 55mm”, is stored in the Solr field name_string_en, which is dynamically assigned to a text_en type:
<dynamicField name="*_text_en" type="text_en" indexed="true" stored="true" />text_enhas the following set of filters:
<fieldType name="text_en" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory" />
<filter class="solr.StopFilterFactory" words="lang/stopwords_en.txt" ignoreCase="true" />
<filter class="solr.ManagedStopFilterFactory" managed="en" />
<filter class="solr.SynonymFilterFactory" ignoreCase="true" synonyms="synonyms.txt" />
<filter class="solr.ManagedSynonymFilterFactory" managed="en" />
<filter class="solr.WordDelimiterFilterFactory" preserveOriginal="1" generateWordParts="1" generateNumberParts="1" catenateWords="1" catenateNumbers="1" catenateAll="0" splitOnCaseChange="1" />
<filter class="solr.LowerCaseFilterFactory" />
<filter class="solr.ASCIIFoldingFilterFactory" />
<filter class="solr.SnowballPorterFilterFactory" language="English" />
</analyzer>
</fieldType>There is a filter called SnowballPorterFilterFactory. This class dynamically loads the Porter Stemmer algorithm, which is generated from a set of rules. These rules are very simple, and the list of exceptions is limited. So, for the word “Lens”, the stemmer creates a singular form, “Len”, which is not correct. A noun that ends with “s” doesn’t necessarily mean it’s plural. Porter knows about “news”, but doesn’t know “lens”.
Solr tries to find “lens” as the singular form of “lenses” in name_string_en, but finds only “len”, which is a different word. This is why “Lens” in the product name doesn’t work. Synonyms would help there a lot.
This article is focused on Hybris 6.4 with Solr 6.1 support. Solr 6.1 is built on top of Lucene 6. Since Solr 6, Lucene has used BM25 as the default similarity method. I explained this algorithm above. In previous versions of Lucene, Solr, and old versions of SAP Hybris, the default similarity class is based on a simplified algorithm. See DefaultSimilarity: http://www.lucenetutorial.com/advanced-topics/scoring.html.
Hybris also disables TF/IDF scoring for some string fields by specifying a custom similarity class. The reason is Hero products — products with a huge boost factor — that need to appear in the expected order in the list:
<fieldType name="string" class="solr.StrField" sortMissingLast="true" omitNorms="true">
<similarity class="de.hybris.platform.lucene.search.similarities.FixedTFIDFSimilarityFactory" />
</fieldType>© Rauf Aliev, July 2017
That is why you need to test search thoroughly after any change in the boost factors and tune the boosts… but search testing is a topic for a separate article. Stay tuned!