

This article is brought by
Olesia Voloshina, EPAM SAP Commerce Cloud Solution Architect.
Сontributors & Editors:
Myles Bunbury, P.Eng, Senior Director, Technology Solutions, Global SAP Customer Experience Lead; Rauf Aliev, Chief Software Engineer, Solution Architect
Recently, our team successfully completed a CCv1 (SAP private cloud) to CCv2 (public cloud on Microsoft Azure) SAP Commerce Cloud (Hybris) migration project for one of our manufacturing customers. Though this was not a new experience for EPAM in general, there are always new things to be learned as unique circumstances, customizations, configurations, etc. generate new problems & challenges to solve. In this article, we summarize the lessons learned and obstacles encountered.
Migration projects are complex and multi-faceted. There are no typical challenges. In this article, we highlight some challenges from the following topics:
- Continuous Delivery for Cloud Portal
- CCv2 infrastructure
- Changes in the project code
Note: While this article covers recent experiences migrating from CCv1 to CCv2, many of the lessons learned here apply equally to an on-premise migration to CCv2.
Continuous Delivery for Cloud Portal
Continuous Delivery (CD) is a process by which code is built, tested, and deployed to one or more test and production working environments. With it, you can continuously deliver to production the code stored in the source code repository in a controlled and reliable manner.
Continuous Integration (CI) is the practice of automating the integration of code changes from multiple contributors into a single software project. CI, while critical for modern software development, has nothing to do with the SAP Cloud Portal. Ergo, we are focusing here mainly on CD processes. Note however that the pipeline is normally called “CI/CD” given that CI and CD processes are often considered as a whole.
Quality Gates determine what conditions a project must fulfill before it can be deployed to any environment. For example, there is a platform called SonarQube for measuring and analyzing source code quality. Such tools are integrated into the CI/CD pipeline.
Jenkins, a popular CD automation tool, was used with SonarQube to ensure only clean, approved code is delivered.
Here are some things you need to keep in mind when setting up your CI/CD process for CCv2:
- Supporting Build Retries
- Dealing with tests that failed
- Enabling/disabling maintenance pages
- Deployment options and data sanitization
Supporting Build Retries
It is useful to automatically trigger a new build if the previous build of the current build configuration has failed. The CI/CD configuration from Cloud Portal does not support such a capability. If the build fails, the Cloud Portal assumes that someone will restart it manually. Jenkins can help here.
The build process may fail for a multitude of reasons. Some problems are temporary in nature while others are permanent. A host-not-found error like this has nothing to do with code or configuration that can be managed by the development team:
java.net.UnknownHostException: modeltimagerepo.azurecr.io However, this error is enough to ruin the build process.
It happened fairly often (at least weekly) and confused the team at first.
We configured our CD through Jenkins so that the build is restarted automatically if the logs contain the errors of this kind. SAP provides Commerce Cloud API supporting getBuildLogs and createBuild commands.
Dealing with Tests that Failed
The manifest file specifies what unit, integration, and web tests are to be executed in the Cloud Portal’s build process. However, this process assumes that the results of the tests should be extracted from the huge build log as plain text messages. This was not convenient for the team.
In the past, CCv2 had build logs available as an XML JUnit report which we were able to parse and reformat. Unfortunately, SAP removed this report and now the only way to extract the details of failed tests was by analyzing the raw console logs.
Enabling/Disabling Maintenance Pages
SAP Cloud Portal provides a way to activate maintenance mode per endpoint. It is helpful if you want to let visitors know that your website is still around and that the maintenance downtime is only temporary.
However, if you have a bunch of websites on different domains, you can’t activate maintenance mode for all of them at once or for a specific subset. You must do this manually for each website in turn.
- Enabling/disabling maintenance pages – Automation is not supported yet; it can be done only manually per each endpoint. Considering that our customer has 14 sites with different domains on the same SAP Commerce Cloud instance, it would be nice to be able to enable/disable maintenance pages in one click and/or automatically.
- Updating of static files (including maintenance pages) and redirect rules – Besides the fact that their loading cannot be automated, manual management of this data is also quite difficult. You cannot download previously uploaded files to see what is now in it (ie. current state). The only procedure available is to upload a new version and then set up it individually for each of your storefronts/endpoints. In our case it was 14 static file sets and the same amount of redirect rule sets. Ultimately, this was pretty time consuming and repetitive.
Deployment Options
When you trigger a deployment process in SAP Cloud Portal, you have a limited set of configurable parameters. Among them are:
- A unique identifier of the build
- Target environment
- Database update mode
- eg. initialization/update/none
- A strategy of deployment
- eg. recreate/rolling update
However, a key missing option we wanted to see was an optional checkbox to enable data sanitization during this deployment.
Data sanitization, or anonymization, is the process of removing personally identifiable information (PII) or sensitive data of any kind from the database. This is essential for privacy and regulatory compliance (eg. GDPR) considerations when cloning data (“copy down”) from the production environment for use in the lower environments. Doing this makes production-caliber data available for the development, QA and performance testing teams, which significantly improves the fidelity and effectiveness of the quality assurance effort across the team.
We added a ‘sanitization.enabled’ configuration property in Jenkins which enables sanitization during the deployment and system update process. To control this, we used Commerce Cloud API’s getProperty and putProperty to ensure that no sensitive data comes to the lower environments.
Database and Data Migration
The migration process from CCv1 to CCv2 often involves migrating from a non-Microsoft database to Microsoft Azure’s SQL database.
This part of the migration is often found to be one of the most challenging steps.
From HANA DB to MS SQL
SAP Commerce Cloud v1 (CCv1) typically uses an SAP HANA database while the newer Commerce Cloud v2 (CCv2) works only with Microsoft Azure SQL database by design. Check if your database queries are database specific and if they are able to work with Azure SQL. The queries using NOW(), LCASE(), and TO_CHAR() functions need special attention.
Also, keep in mind that the build process on SAP Cloud Portal , including the tests run, uses HSQLDB, not Microsoft Azure DB. Your code should therefore be tested on HSQLDB as well.
Data Migration: Expectations and Reality
SAP has not adequately defined and documented the data migration process from a technical standpoint for developers. This is mostly due to the fact that the CCv1-to-CCv2 database migration is supposed to be handled by SAP themselves. Consequently, the details of the data migration process is opaque to the development team, which caused many concerns within the development team and limited collaborative opportunities.
The process turned out to be different from what we initially thought. We thought that SAP would create an empty database on CCv2 and populate it with the data from the CCv1 database applying some transformation “magic” during the process. After the data was migrated, the system would be updated and tested with the new database.
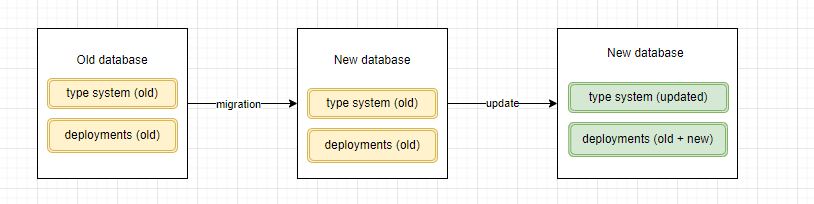
It turned out that the process is actually quite different.
SAP re-initializes the system on CCv2 and migrates data from CCv1 to this empty database.
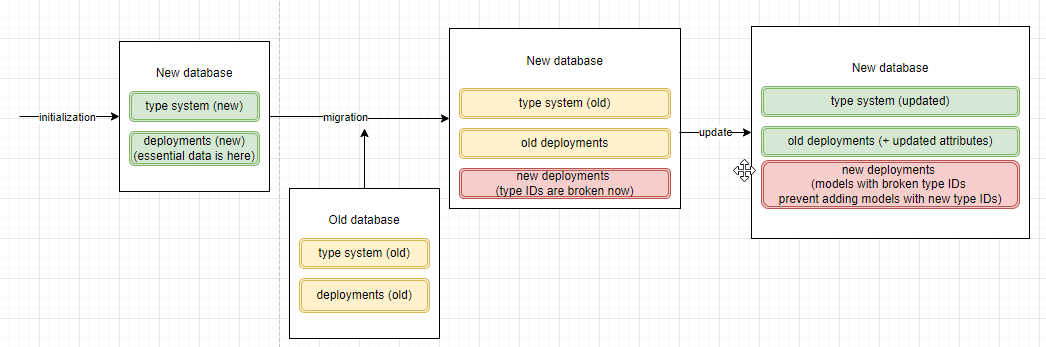
The key point here is re-initialization.
In our case, we got a lot of errors during the system update. Not all data items were created automatically due to constraints (eg. unique attributes). The failed inserts then created cascading failures due to unresolved dependencies. Consequently, we had to clean such tables to remove conflicting entries and re-apply impexes.
Another challenge related to deleted attributes. The database model is supposed to be in sync with the metadata definition in SAP Commerce. It is so until you need to remove the attributes. In SAP Commerce, persistence framework data model changes are not handled nicely when it comes to deletions and changing attribute types.
As a result of re-initialization, such attributes were not created as database columns in the CCv2 database; however, their attribute descriptors remained in the migrated type definitions. By applying changes directly to the CCv2 database, bypassing SAP Commerce, we were able to resolve the issue.
Three key findings stand out in the results of this exercise:
- A deep understanding of SAP Commerce persistence is crucial for success
- Initialization scripts should be relevant and well-maintained
- There may be a need to clean up data during and after the process
To succeed, it is important to discuss all aspects of the process with SAP’s engineers and managers, including all risks and liabilities.
CCv2 Infrastructure
The standard SAP Commerce Cloud offering provides three environments: development, staging and production. Each comes with an Azure SQL database, Azure Blob storage for media, Solr Cloud cluster, Kibana for logs, and Dynatrace for monitoring. Almost all of these services come preconfigured by SAP. Unfortunately, in many cases, it is not possible to customize these services even with SAP support.
For example, we discovered that it is not possible to tweak the HTTP connector parameters anymore in Apache Tomcat. In our case, we were seeking how to redefine the relaxedPathChars and relaxedQueryChars HTTP Connector attributes specifying what additional characters to allow in order to prevent Tomcat from rejecting requests that had some special characters in the URL. For example, using curly or square brackets in the URL.
Some configuration parameters are manageable, but the capabilities are limited. They relate to Apache and upstream services:
- IP filter sets to restrict access to endpoints
- Redirect rules, per endpoint
- Cache settings
It is worth mentioning that only ‘Redirect’ and ‘RedirectMatch’ directives are supported to manage your redirect rules. If you want to use ‘RewriteRule’ directives, be prepared that it won’t work on CCv2. Here you can find some advice from the SAP on how to work around this constraint: https://launchpad.support.sap.com/#/notes/0003080815.
Solr: Versions and Configurations
For Solr, you can select one of the supported Solr versions and specify what version to use in the manifest file. By default, if not specified, the system uses the Solr version associated with the version of the platform. Note that this is not always the latest one version of Solr available.
In our case, we had to upgrade Solr to the newest version due to the log4j-related security issue. SAP has since released an appropriate patch, but at that time this was not available and we needed to perform such an upgrade manually.
If you have customized the default Solr configuration, test it thoroughly to make sure it works with the supported Solr version. In our case, the default Solr configuration on CCv1 differed from the default Solr configuration on CCv2, which caused issues.
Also, please remember you can’t use any custom modules with Solr.
The root cause was in <str name=”df”>text</str> which was present in the default CCv1 configuration but not included into the CCv2 default Solr configuration file. This parameter allows Solr to process the request with some defaults even if it could not parse everything in the search query. You can read the details here: https://stackoverflow.com/questions/32088401/how-to-do-a-complex-phrase-keyword-search-in-solr#:~:text=The%20error%20message%20no%20field,no%20df%20parameter%20supplied%20either.
We also found that one of the boost factors in the Search Profiles (part of Adaptive Search) had a very small number which was stringified in scientific notation which Solr had not understood (see AbstractFacetSearchQueryPopulator.convertBoostField for details). So, we implemented a patch introducing a validation interceptor for BoostRules to avoid such issues.
Azure Blob Storage: Be Careful with Empty Files
We were surprised when we found out that CCv2 couldn’t handle empty media files correctly. The problem occurred when our application read a media file that was created as empty. The CloudAzureBlobStorageStrategy threw an error:
java.lang.IllegalArgumentException: The value of the parameter 'blobRangeOffset' should be between 0 and -1Taking this peculiarity into account, we modified our code to handle empty media files.
Changes in the Code
Overall, major changes in the code were not necessary to make our system work on CCv2. The code is essentially the same as we used with CCv1.
Multiple Environments with Multiple Property Files
According to the approach recommended by SAP, the properties in the manifest file can be split into a set of shared properties (for all environments and nodes), aspect-specific properties (such as admin, frontend, etc.) and environment-specific properties. In the configuration file, the environment is called a “persona”.
You can specify only three values for persona: “development”, “staging”, and “production”. We could not find a way to define different parameters for different environments of each kind. For example, if you have more than one development environment or more than one staging environment, they will share the same set of properties because a persona cannot be set to “development2”, “staging2”, or “performance1”.
Of course, you still can use a hcs_common service or static files on Cloud Portal to store environment-specific properties, but both of them would need to make changes in the core logic of the application.
To keep the usual methods of loading properties undisturbed, we noted that it was feasible to wrap additional logic to support the loading of alternative property values:
- Customize the way SAP Commerce Cloud loads properties (eg. hybrisProperties bean) by adding some “environment ID” prefix for all environment-specific properties and then handle it with the properties loading process
- Add a capability in your deployment pipeline to retrieve the required properties file per selected environment and put all properties from here into hcs_common using APIs just before deployment
Configurable Cache Regions Size
Before go-live, SAP performed their mandatory Cloud Readiness Check. The most important point here was related to our cache configurations. Specifically, SAP recommended making cache regions configurable.
When the cluster is scaled up, the available memory is also increased. Consequently, it is desirable that the cache is also automatically increased to match the additional memory available. This means that the sizes for caches should be declared as follows:
regioncache.entityregion.size=#{100000 * (T(java.lang.Runtime).runtime.maxMemory() / (1024 * 1024 * 1024 * 8.0))}Cloud-Specific Extensions
There are extensions automatically injected into the system by the CCv2. Some of them can be enabled or disabled in the manifest file. Some are added automatically and transparently during the build process on Cloud Portal. Examples include:
- azurecloud, azuredtu, azurehac
- businessmetrics, ordermetrics
- ccv2internal, ccv2sla
- cloudstorage
- solrcloudbackup
- modelt
These extensions may create cronjobs, event listeners, and interceptors which were not part of the system on CCv1. For example, ‘DoNotDisable_CCV2EDPHeartBeat’ and ‘solr-cloud-backup’ are cronjobs added to monitor the system and backup Solr. Any issues with the entities created by the SAP modules are resolved by the SAP.
Useful links:
- Checklist for successful migration: https://www.sap.com/cxworks/article/2589633410/checklist_for_succeeding_with_sap_commerce_cloud
- ImageMagick for CCv2: https://help.sap.com/viewer/403d43bf9c564f5a985913d1fbfbf8d7/v2011/en-US/fba094343e624aae8f041d0170046355.html
- List of properties, managed by SAP: https://help.sap.com/viewer/1be46286b36a4aa48205be5a96240672/v2105/en-US/a30160b786b545959184898b51c737fa.html?q=managed%20properties
- Order of properties application from different places in CCv2: https://help.sap.com/viewer/1be46286b36a4aa48205be5a96240672/v2005/en-US/b35bc14a62aa4950bdba451a5f40fc61.html#loiod090fb3dd48a418d967a1dfdca9fcac6
How to customize readiness check: https://help.sap.com/viewer/b2f400d4c0414461a4bb7e115dccd779/v2105/en-US/b57442f241f443c489fee95a8bb4f5ae.html