Enhanced multi-word synonyms and phrase search in hybris
Introduction
A synonym is a word having the same or nearly the same meaning as another word or other words in a language. In any search engine, handling synonyms is very important. In SAP Hybris Commerce, synonyms are handled by Apache SOLR, the built-in search engine. There are issues with the default implementation. This article explains on how to overcome them. The phrase search is a feature that moves the documents (products in our case) higher in the search results if their attributes contain the exact request. The default implementation is also very basic. In this article, I present my PoC that demonstrates the better synonym handling and enhanced phrase search in SAP hybris Commerce.Challenge
Synonyms
There is a well-known limitation on how SOLR works with the synonyms. The one-word synonyms are processed nicely, but when we try to use multi-word synonyms, you will definitely face the issues. Simply put, the multi-word synonyms aren’t working as expected. There’s a reason for that: the synonym module start working after tokenization part is done. Let’s look at the example.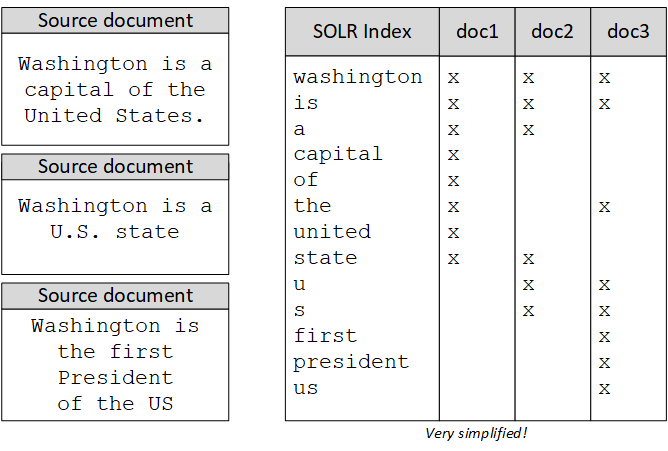 There are two ways on how SOLR handles synonyms: index-time and query-time synonyms processing. In the default hybris configuration, both are configured in the same way.
In the example above, we may want to create the following synonyms:
There are two ways on how SOLR handles synonyms: index-time and query-time synonyms processing. In the default hybris configuration, both are configured in the same way.
In the example above, we may want to create the following synonyms:
 I would like to highlight the following points:
I would like to highlight the following points:
- Synonyms may be equivalent in terms of their role (primary/secondary)
- Synonyms may have more than one word in both sides.
- Synonyms may have stopwords (such as articles) and special symbols (such as punctuation marks) as an integral part of them.
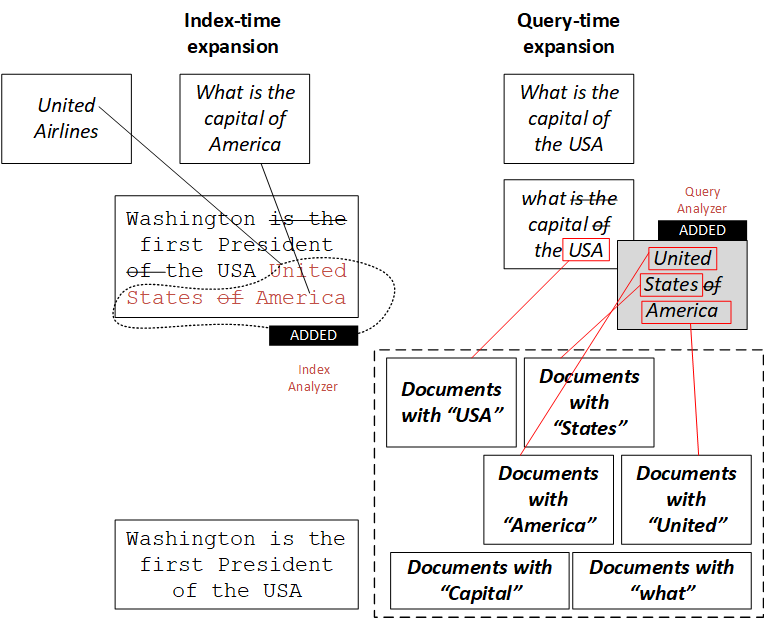 Query-time expansion
Query-time expansion simply replaces words in the query token stream with their synonyms.
However, it has the negative side effects. First, the IDF of rare synonyms will be boosted, causing unintuitive results. The documents containing rare words are higher in the solr search results. It is quite natural, but with the synonyms it may confuse the user, putting documents with the original high-frequency word deeper in the search results.
The details of the problems are greatly explained in this article.
Index-time expansion
Index-time synonym expansion is an alternative to query-time expansion, but expanding synonyms at index-time has two major problems.
First problem is called ‘sausagization’. The roots of this problem are in the way of how lucene works.
For example, if index-time synonym expansion “USA => United States” is performed on a document “
Query-time expansion
Query-time expansion simply replaces words in the query token stream with their synonyms.
However, it has the negative side effects. First, the IDF of rare synonyms will be boosted, causing unintuitive results. The documents containing rare words are higher in the solr search results. It is quite natural, but with the synonyms it may confuse the user, putting documents with the original high-frequency word deeper in the search results.
The details of the problems are greatly explained in this article.
Index-time expansion
Index-time synonym expansion is an alternative to query-time expansion, but expanding synonyms at index-time has two major problems.
First problem is called ‘sausagization’. The roots of this problem are in the way of how lucene works.
For example, if index-time synonym expansion “USA => United States” is performed on a document “
the first President of the USA is Washington
| Position: | 1 | 2 | 3 |
| Original: | USA | is | Washington |
| Synonyms: | United | States | Of |
{ id : "doc1" , description_text_en: "Washington is the first President of the USA"}
USA => United States of America
first, of, presid, state, unit, washington, america
Phrase search
In hybris, phrase match can be boosted, and the phrase boost factor is configurable. However, there is an important point on what the phrase is. If you search for “the first president of the United States”, the document containing these words can be boosted (placed higher in the search results) only if the document contains all these words in the exact order. For example, if you use the phrase “Washington is the first president of the United States”, the document containing the whole phrase will take the first position, and it is a right thing, but the documents containing the parts of this phrase (“first president”, “president of the United States” etc.) won’t be boosted at all.Solution
In my solution, the query processing was moved from SOLR to hybris. In SOLR, the filters are off both in indexing and query modes. The module adds partial phrases to the query and their synonyms. For example, for the query ”the first President of the USA
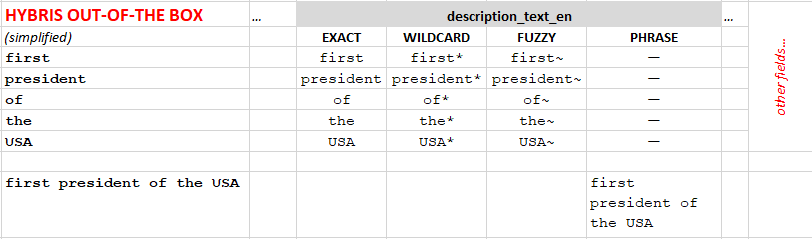 You see that only the whole query is considered as a phrase. There is no such thing as “sub-phrase” with the higher boost factor.
In my solution, I create sub-phrases for the request:
You see that only the whole query is considered as a phrase. There is no such thing as “sub-phrase” with the higher boost factor.
In my solution, I create sub-phrases for the request:
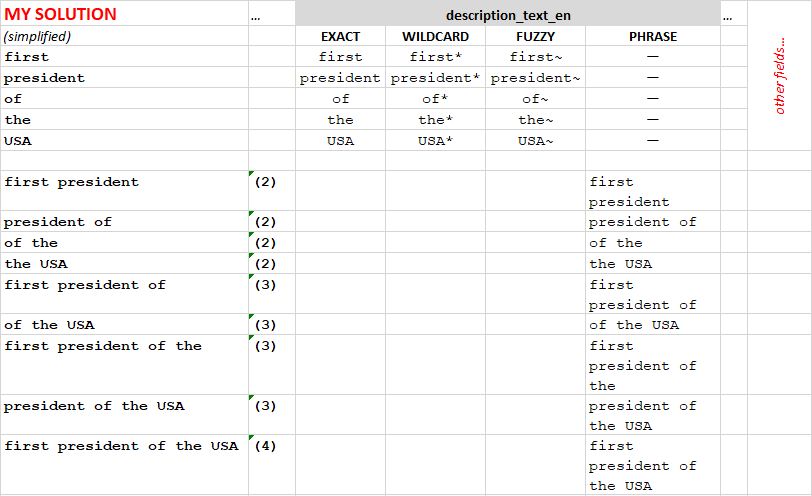 After that, my code finds the exact match of the synonyms for the words and sub-phrases and creates the additional phrases for the search:
After that, my code finds the exact match of the synonyms for the words and sub-phrases and creates the additional phrases for the search:
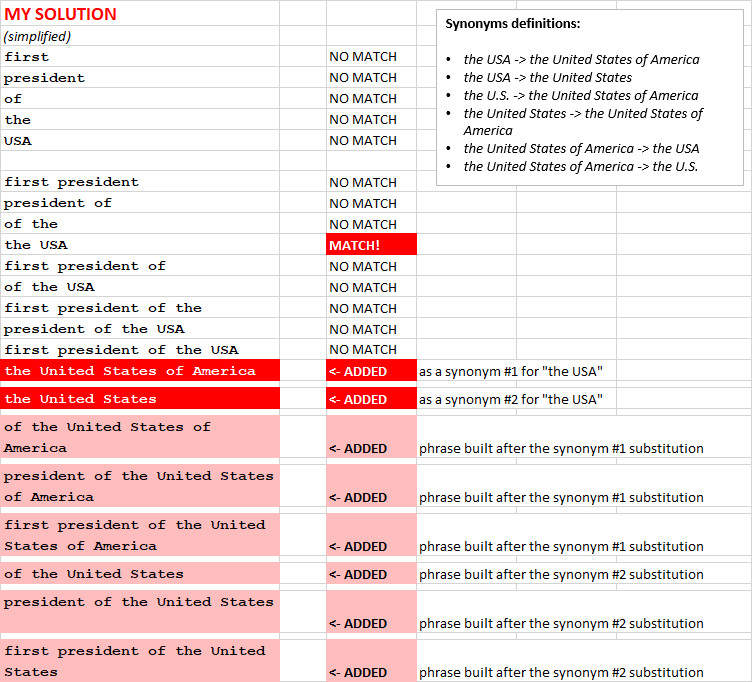 In the example above, “the USA” was found in the list of synonyms, and new queries were added in the list. Note that these extra phrases contain the synonyms in different combinations with the words from the original phrase (“the USA”).
In the example above, “the USA” was found in the list of synonyms, and new queries were added in the list. Note that these extra phrases contain the synonyms in different combinations with the words from the original phrase (“the USA”).
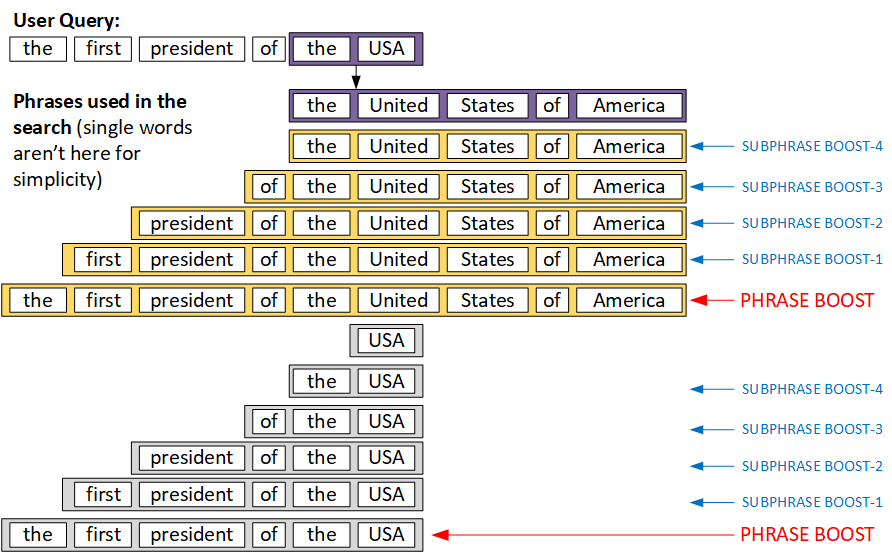 The phrase matches (last 17 items) has higher boost factors than word matches (first five items). Among the phrases, longer phrases have higher boost factors than shorter phrases.
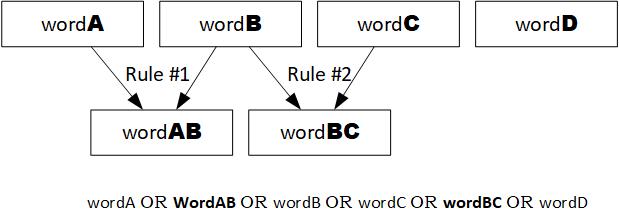
There is a special case when the synonyms are overlapped:
The phrase matches (last 17 items) has higher boost factors than word matches (first five items). Among the phrases, longer phrases have higher boost factors than shorter phrases.
There is a special case when the synonyms are overlapped:
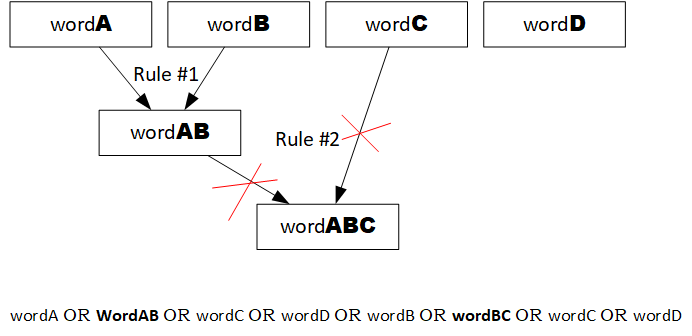
 However, the replacements can’t be used to create new replacements:
However, the replacements can’t be used to create new replacements:
Examples
In the example below, there is a rule saying that “Flip-flops” (or flip flops) and “Sandals” are synonyms. Flip-flops contains two tokens (two words -> one word), so the OOTB synonyms won’t work. In this solution, the custom query contains both “sandals” and “flip-flops” (or “flip flops”).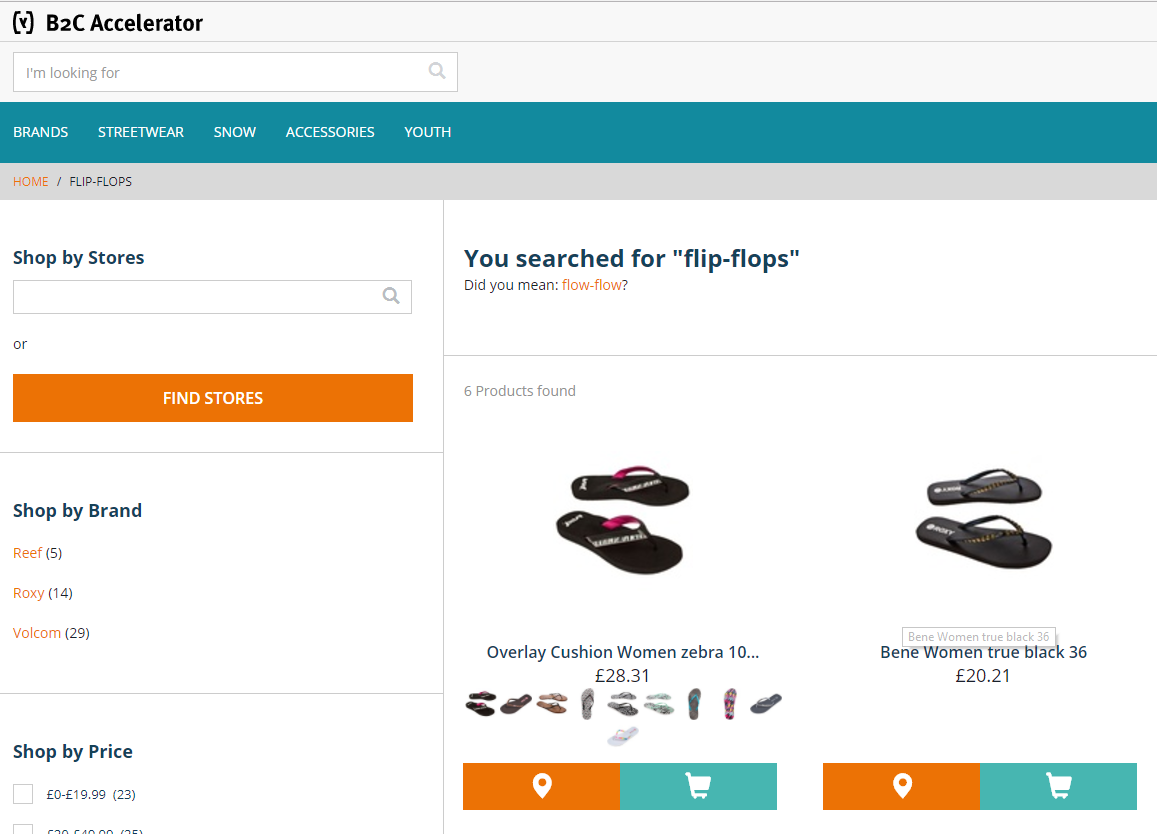 In the example below, “slippers” and “slip on” are synonyms (here we see the rule “one word -> two words”):
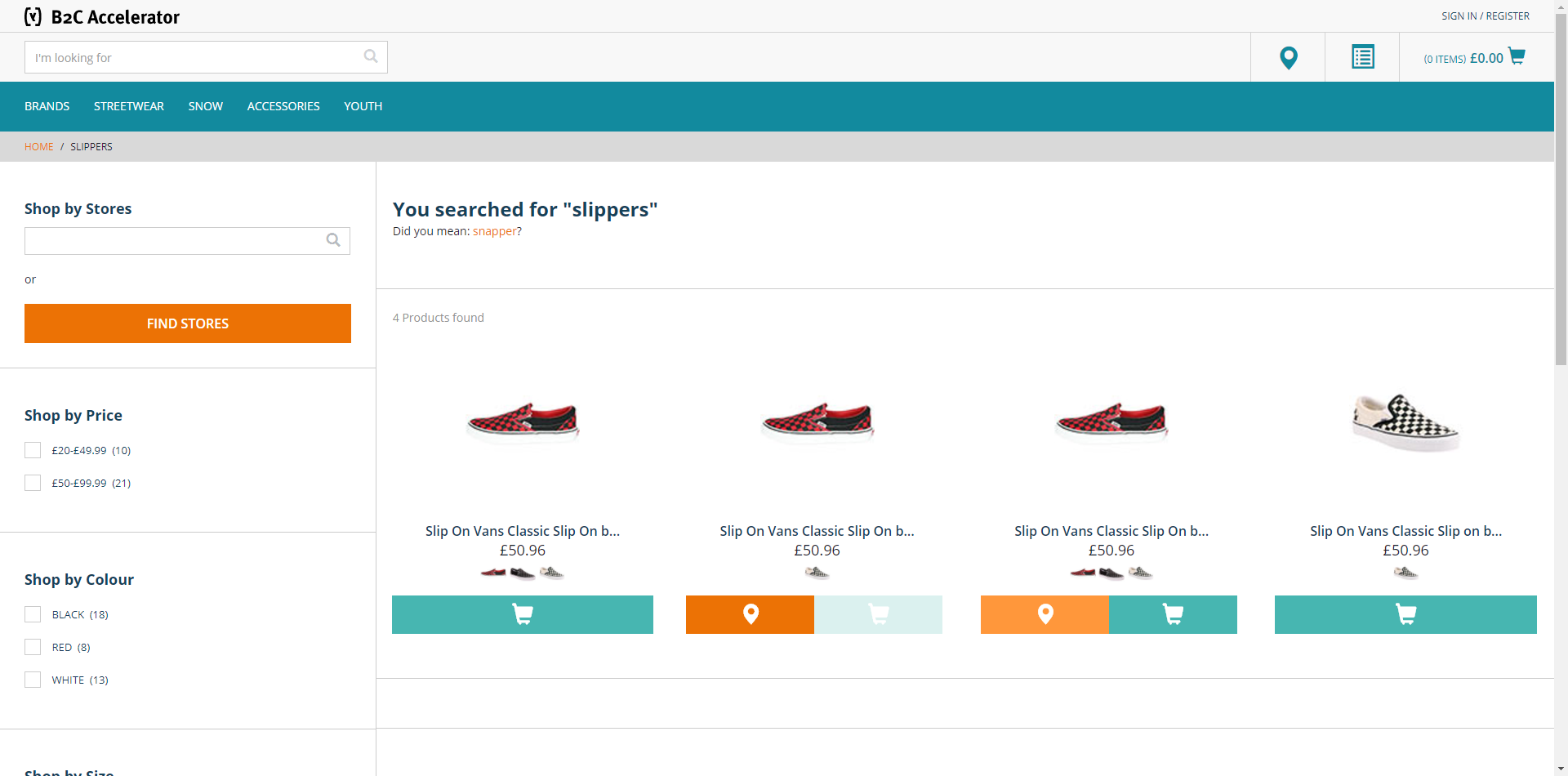
In the example below, “slippers” and “slip on” are synonyms (here we see the rule “one word -> two words”):
Phrase search
In the example below, I demonstrate how sub-phrase search works. If you search “men t-shirt logo”, in the default hybris configuration, you will get all products containing “men”, “t-shirt” and “logo”, but these products will be sorted by relevancy, taking into account how many times these words were used in the product attributes and how rare they are. In the default configuration, you will have the following products for the request “men t-shirt logo”: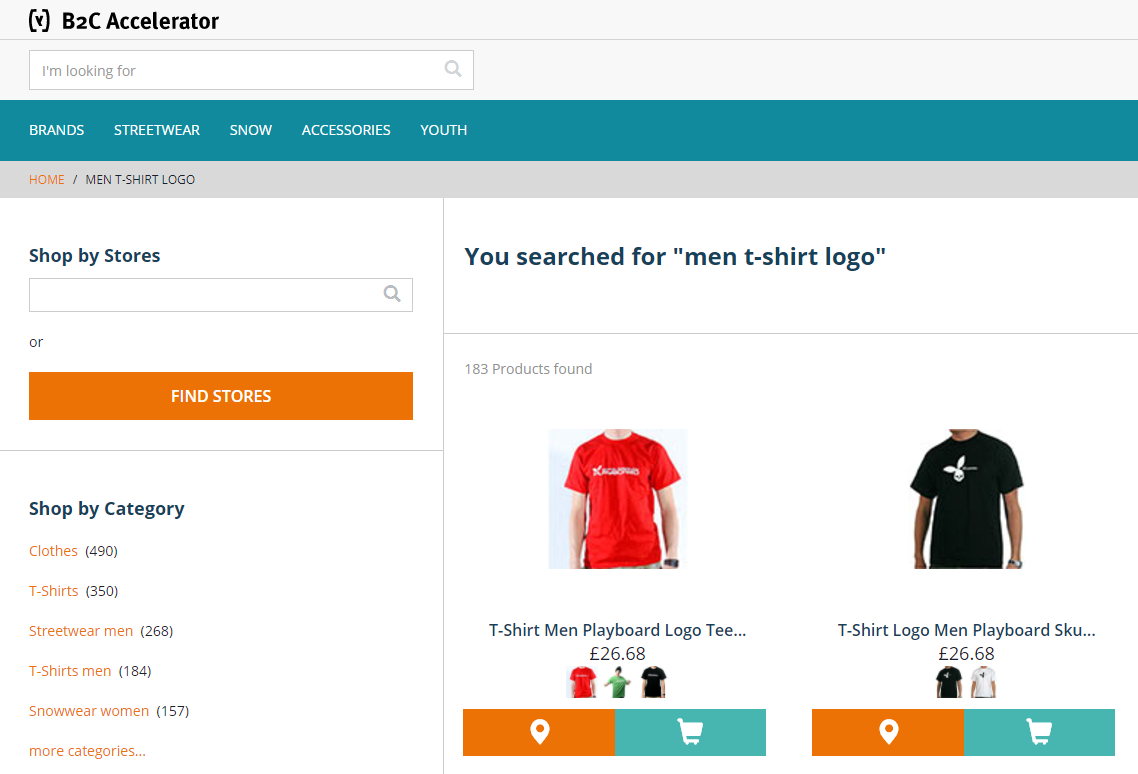 Note that the black t-shirt is on the second place. In my solution, this product is higher in the search results because its name contains “t-shirt logo” as a sub-phrase of the original request (“men t-shirt logo”). (This example is not the best because of the demo database that comes with hybris is small and simple; I can’t use anything else than hybris provides OOTB).
Note that the black t-shirt is on the second place. In my solution, this product is higher in the search results because its name contains “t-shirt logo” as a sub-phrase of the original request (“men t-shirt logo”). (This example is not the best because of the demo database that comes with hybris is small and simple; I can’t use anything else than hybris provides OOTB).
Video
© Rauf Aliev, August 2017

Navigation | hybrismart | SAP hybris under the hood
9 August 2017 at 12:53
[…] SOLR (partial update, multi-line product search, static pages and products in the same list, solr 6 in 5.x, 90M personalized prices, 500K availability groups, solr cloud, highlighting, 2M products/marketplace, more like this, concept-aware search: automatic facet discovery), explaining relevance ranking for phrase queries, enhanced multi-word synonyms and phrase search […]
Alessandro Behling
9 August 2017 at 13:16
I came across this issue a few times and as you said, there is no easy answer. My main concern with turning off the filters in the OOTB SOLR which we know is extremely fast processing the data, how do you account for lost performance? Assuming your solution still needs to get hold of all the documents in SOLR in order to do it’s filtering in hybris shores, do you ship all that data over the network into the hybris node dealing with the request (assuming SOLR is a different box) to only then process the result set sent back to the customer.
Rauf Aliev
9 August 2017 at 13:20
My solution preprocesses the query before sending it to solr. All other things remain the same as they are in the OOTB. The preprocessing doesn’t take much resources, so I don’t expect any significant impact in terms of performance
planetofadventure
9 August 2017 at 13:34
I see, I understood that incorrectly initially, that makes a lot more sense now. Thanks
Lenar
9 August 2017 at 15:31
In the article, are you working with SynonymFilterFactory or SynonymGraphFilterFactory in solr?
Rauf Aliev
9 August 2017 at 16:21
First one + managed synonyms because they are preconfigured in hybris solr (and in solr OOTB). Second one is not in the default set up. I am aware of it, of course. It worths mentioning in the separate article. Anyway, it solves only one problem we have with synonymfilterfactory.